MLOps or Machine Learning Operations are a combination of best processes and practices that businesses use to run AI successfully. As a core function of Machine Learning (ML) engineering, MLOps focuses on establishing technologies and systemizing procedures for a scalable and centralized method of automating the management and deployment of machine learning models in a productive environment. While it is a relatively new field, MLOps is a collective effort that captured the interest of data scientists, DevOps engineers, AI enthusiasts, and IT.
Applying the best practices, i.e. MLOps, improves the quality of Machine Learning and Deep Learning modes and clarifies management procedures. In doing so, it streamlines the deployment of Machine Learning and Deep Learning applications in massive production environments. This way, grouping applications with similar needs and administrative requirements becomes simpler.
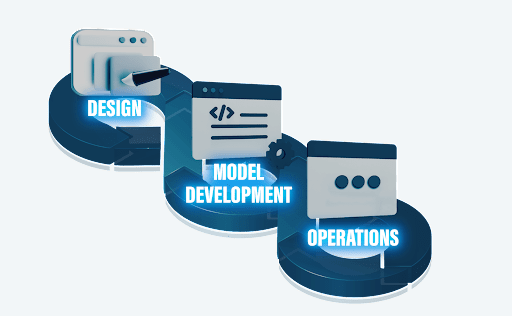
MLOps is progressively evolving into a self-sustaining method for the creation and quality control of ML and AI solutions. Since MLOps applies to the entire ML lifecycle management, data scientists and machine learning engineers can collectively work to optimize the speed of model development and production. This is done through deploying continuous integration and deployment (CI/CD) processes, along with established ML applications of data gathering, monitoring, validation, and governance.
The goal of MLOps is to combine the release cycles for ML and software application releases. MLOps streamlines testing of ML artifacts including data validation, ML model testing, and model integrating testing. Additionally, it allows the application of agile principles to machine learning models. MLOps also minimizes technical debt across ML applications.
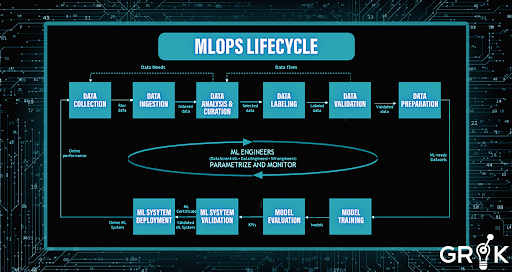
Creating successful ML applications is still difficult considering how ML/AI is scaling into new models and forming new industries. Businesses are unaware of the full-scale advantages of AI because applications aren’t deployed; or if they are, the deployment isn’t sufficiently complete to meet their business needs. Building ML/AI models requires multiple languages and an array of teams. The ML lifecycle involves complicated factors and processes including data gathering, model creation, CI/CD, model tuning, model deployment, model diagnostics, governance, and more. As part of ML Lifecycle management, data scientists, data engineers, ML engineers, and other relevant departments are required to collaborate and exchange data.
Hence, there is a need to establish standardized practices and processes used in designing, creating, and implementing ML applications to ensure that they are all in sync and working efficiently together. With MLOps deployment, businesses can seamlessly deploy, track, and update models in production. MLOps embodies the entire machine learning lifecycle including experimentation, repetition, and constant improvement of the ML lifecycle.
With MLOps, the production and deployment of ML applications become efficient and scalable with less risk. With MLOps, data teams achieve quicker model creation without compromising quality. Teams can also deploy and produce faster. Additionally, MLOps allows extensive scalability and management where teams can oversee, control, manage, and monitor multiple applications for ongoing integration, delivery, and execution.
To be precise, ML pipelines are reproduced through MLOps, allowing more tightly-coupled teamwork across data teams. This reduces misunderstanding among DevOps and IT and speeds up release.
ML applications are typically subjected to regulations and drift checks. Since MLOps provide substantial transparency and quicker response to regulation requests, ML models follow an organization’s or industry’s policies.
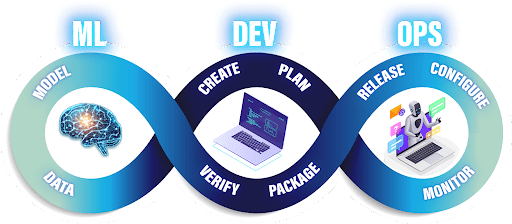
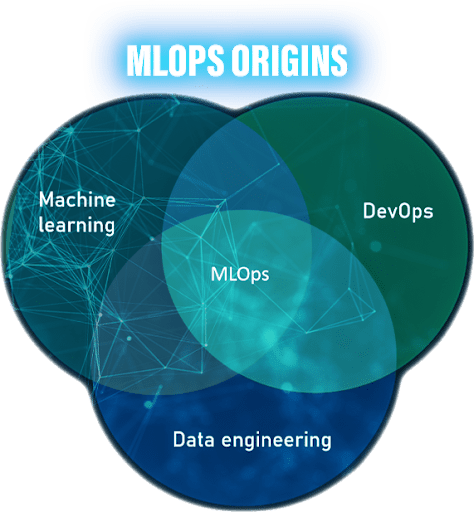
Machine Learning Operations is an entirely new set of engineering practices specific to machine learning projects. Their basic principles in software engineering are derived from DevOps principles. Whether it is ML or DevOps, both yield premier software quality, quicker patching and release, and improved customer service.
Compared to DevOps, MLOps has an experimental nature wherein Data Scientists and ML/DL engineers may adjust features, such as parameters and models, while simultaneously monitoring and managing the data and the code base for reproducible results.
When embarking on an ML project, it is important to remember that the team needed to build and deploy models in production won’t be composed of software engineers only. In addition to developers, the team usually includes data scientists or ML researchers, team members who focus on exploratory data analysis, model development, and experimentation. While these individuals might be experts in their field, they might not have the experience or knowledge needed to build production-class services.
To ensure that an ML system is functioning properly, it is necessary to test the system thoroughly. This involves not only testing the code, but also validating the models and training the system. Unit tests and integration tests can verify that the code is working as expected.
Before a machine learning (ML) model can be deployed as a prediction service, it must go through a multi-step process that data scientists typically handle manually. This process can be automated using a machine learning pipeline, which helps to ensure that the model is retrained and deployed correctly.
ML models in production can have reduced performance not only due to suboptimal coding but also due to constantly evolving data profiles. Models can decay in more ways than conventional software systems. There are several ways to prevent this from happening, including retraining the models on a regular basis and using drift detection algorithms.