Since the Turing test was invented in the 1950s, along with Turing’s other contributions, there have been 2 significant AI winters, where AI enthusiasm peaked but significant challenges then deflated expectations and subsequent funding and industry applications. The first AI winter followed a period of significant press coverage but technical hurdles followed by a report by DARPA in the early 1970s that among other criticisms argued that “in no part of the field have discoveries made so far produced the major impact that was then promised.”The second AI winter followed a resurgence of AI interest and funding in the early 1980s, which was focused more on commercial applications vs broad cognitive domains like the goal of ‘machine translation’ preceding the first AI winter.
This reemergence posited that a ‘top down’ knowledge architecture combined with carefully designed flexible rules, called ‘Expert Systems’, could solve executive planning problems in financial planning, medical diagnosis, geological exploration, etc. In 1984 the AAAI conference foreshadowed the coming second AI winter, “This unease is due to the worry that perhaps expectations about AI are too high, and that this will eventually result in disaster. I think it is important that we take steps to make sure the AI winter does not happen […].” The second AI winter did indeed occur and lasted almost two decades, ending with the emergence of Deep Learning.
Each AI winter encountered has led to dramatically reduced funding, research, and beneficial industry applications, which at Grok, we are desperate to avoid. Nevertheless, ML and AI has made significant and lasting improvements in industries as diverse as biomedical research and automotives. Some of the same challenges that led to earlier AI winters threaten future progress, and in particular threaten a targeted AI winter with IT/DevOps. For almost 10 years the language of AI has once again started emerging in marketing and positioning, starting with a few niche software startups and leading to a pervasive use of the language of AI across most ITOPS and IT Service Management domains. The term AIOPS has become ubiquitous and meaningless. There are 3 key traps for applied AI practitioners that threaten to derail forward progress by under-delivering on expectations, possibly kicking off another broad AI winter or at least a more focused AI winter in the markets connected to AIOPS.
The first trap is trying to solve problems in the cognitive domain with analytics tools. For a system to be intelligent it must demonstrate (1) self-learning, (2) flexibility, and (3) adaptability. Many early ‘marketeers’ included some ML but mostly analytics toolkit and told industry colleagues that ‘the sky’s the limit’. Other early attempts at AIOPS centered on either a single domain (like anomaly detection) or a rules-centered approach (similar to ‘expert systems’). If a system can not learn without explicit rules, even rules that are recommended, it is not a learning system. Any rules based approach risks the fate of the prior generation of ‘Expert Systems’. Similarly any system that does not exhibit cognitive flexibility, a demonstrated ability to choose sensible actions from conflicting knowledge, is not intelligent. And any system that can’t take action based on causal inferences is not intelligent. Anything short of an application of intelligence in a particular domain may lead to incremental improvements but will not live up to the potential, or the hype of AI.
Even the targeted use of particular intelligent algorithms (IAs) from old school Random Forests or Clustering algorithms, to the latest XGBoost or DeepLearning algorithms, will not generate industry-shaping results; intelligent systems are needed. Most use cases or processes that could benefit from a very targeted approach have already been highly optimized by other means, e.g. human augmented workflows. Indeed a single LA takes a fixed format input stream and generates behavior across a fixed domain. Even the most advanced LAs with observable, tangible results (like generative LAs killing it on Go! games) are constrained by the fixed parameters of the game rules. In life, rules are fuzzy. In life, information is sparse and often conflicting. Flexibility requires connectedness via chains of sensory inputs, cognitive tasks, together with opportunities for external feedback and learning/synthesis.
So fundamentally Applied AI requires a sensible cognitive architecture. Cognitive architecture research began as a part of general AI aimed to incrementally build up to a general AI system by first demonstrating reasoning across different domains, developing insights, adaptability within new situations, and self-reflection. Hundreds of competing CAs have been researched, published, though rarely commercialized over the past 25 years. Rather than searching for a unifying cognitive architecture fit for generalAI, the Grok research team has taken the earlier work as a template but confined our goal to accomplishing a particular domain of use cases, or a process domain in business terms. More about the Grok Meta-cognitive Architecture below.
It’s obviously not enough to slap on some ML tools to an existing product or use case and expect transformative results. Such novel approaches don’t work and more importantly threaten the growing contribution of AI to industry.
IT infrastructure has rapidly evolved over the last decade, and as a result important specialized tools have been developed and an entire dedicated industry has grown up to serve the need for monitoring these IT systems and services in order to keep them operational and efficient.
These IT Operations (ITOPS) tools and techniques developed from rudimentary monitoring tools used to confirm that systems, networks, and specific apps were functioning within broad but acceptable parameters and were available to users. In parallel, IT Service Management (ITSM) tools emerged to help organizations track and guide the work performed by people doing work in ITOPS.
These early instruments evolved further into specialized software tools (performance monitoring) that measure system performance and degradation and simulate end-user transactions as a way to project errors.
In the 2000s an additional branch of ITOPS platforms emerged that focused on consolidation of monitoring data (events, logs, performance) across the systems to provide a single or business view of services and their availability with an implicit promise to correlate the information together.
Any organization will likely have several tools simultaneously monitoring its infrastructure, with significant overlap; moreover, these tools will often create unnecessary infrastructure events and questionable alerts. Under these conditions, while IT teams can tell by the high severity events that an Incident has occurred ,because of the “noise” included in the stream of events, operators are still unable to adequately diagnose the root cause and often fail to respond decisively to it. Each Incident often generates multiple critical events in each monitoring platform, since each platform covers different layers of the service (network, hosts, storage) and different platforms have different operational data domains (logs, eventing, performance polling).
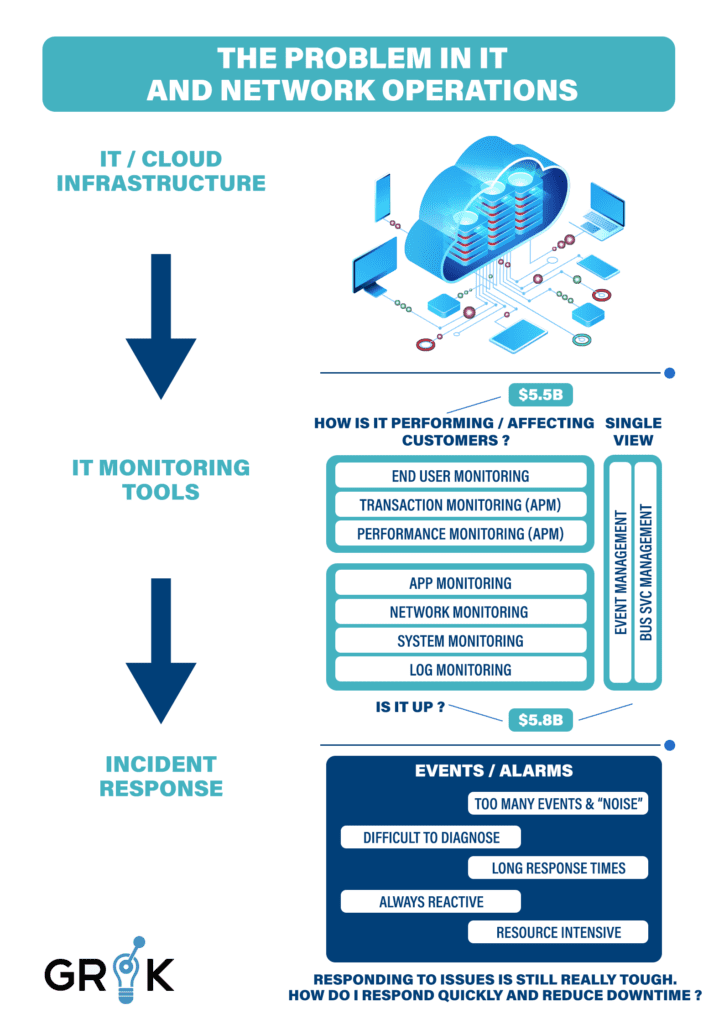
Therefore current practice demands that IT teams adopt a reactive posture, continuously “firefighting” among the critical events, and other alerts and warnings generated by poorly correlated information from overlapping monitoring tools. This solution requires deployment of far too many organizational IT resources to achieve incremental benefits to service availability and service delivery to end-users.
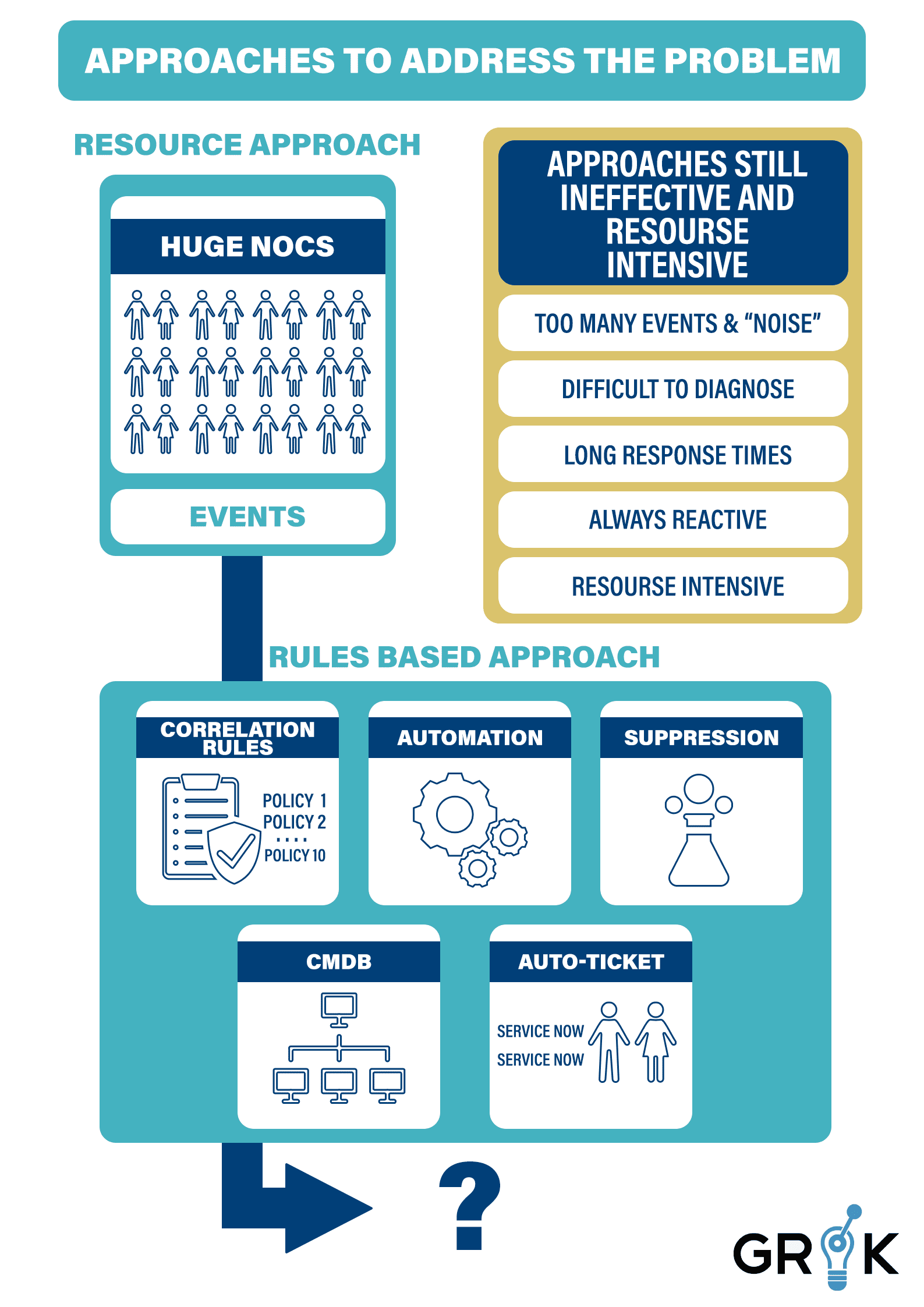
To better utilize their IT teams and resources, organizations have employed several logical strategies, but each of these approaches has its own shortcomings.
As the information age accelerated, most organizations built large network operations centers (NOCs) and hired an ever-increasing number of operators that grew in lock-step with their business growth. In some industries, thousands of operators was the norm, all responding to events that came from the monitoring systems. This strategy of IT resource was inefficient at the outset of the information age, but as services became more complex, the amount of overlapping and duplicate work driven through the ITOPS process grew with that complexity
Some organizations adopted event-suppression protocols to mute all low-severity and duplicate events. This allowed their IT teams to concentrate resources on high-severity and critical alerts.
This practice used “war rooms,” wherein a 20- or 30-person IT team would troubleshoot and remediate each ‘critical’ Incident. This strategy organized teams around a reactive rather than a proactive IT posture but proved to be too resource-intensive; while early warnings were ignored in order to focus, few Incidents were therefore prevented..
Among the emerging options, some organizations embraced a rules-based strategy that made use of a new generation of tools. IT teams would manually script rules to correlate events based on organizational knowledge or automated discovery of the organizational network’s topology and services.
This practice provided some reduction in event volumes by grouping events based on these rules,, but building enough rules proved impossible with incomplete CMDBs and ageing rules that needed continuous updating. From these partially-correlated event-streams, ITOPS teams built auto-ticket and automation rules to improve remediation times. Ultimately, this observability-centered architecture proved inefficient and ineffective for digital infrastructure of scale because the marginal efficiency gains came at a high initial cost for rule development and a substantial maintenance burden for each type of rule required up the stack.

In the quest for ‘observability’, organizations lost site of the fundamental problem with the underlying architecture. No matter how many episodes of Sesame Street we force an earthworm to watch, it will never be able to form itself into the letter ‘C’.
Consequently, organizations were left only slightly better off than in the earliest days of the Information Age and still faced the same critical issues of IT resource allocation and service quality.

In spite of the several strategic investments to improve IT resource allocation and the several ITOPS observability solutions available in the marketplace, IT Operations teams are still extremely reactive and slow. Even solutions that help to improve the IT team’s ability to respond to events and alerts, such as correlating, auto-ticketing, and war room troubleshooting, still require significant resources to staff, develop and maintain.
None of the solutions are scalable in today’s radically changing IT environment.
None bridge the gap.
The founders of Grok have taken a fundamentally different and uniquely innovative approach to solving this problem. They have designed and built a revolutionary new system employing a meta-cognitive model (MCM) that mobilizes AI and Machine Learning to sort through all monitoring noise and successfully identify real problems, their causes, and to prioritize them for response by the IT team.
In order for Grok to be successful, the founders realized that AI and Machine Learning had to be the central elements of any event-processing design concept and not merely peripheral components. The new approach could not rely on a rigid rules-based strategy derived from earlier event management systems or even from some first generation AIOps.
Send video link to:
Send video link to:
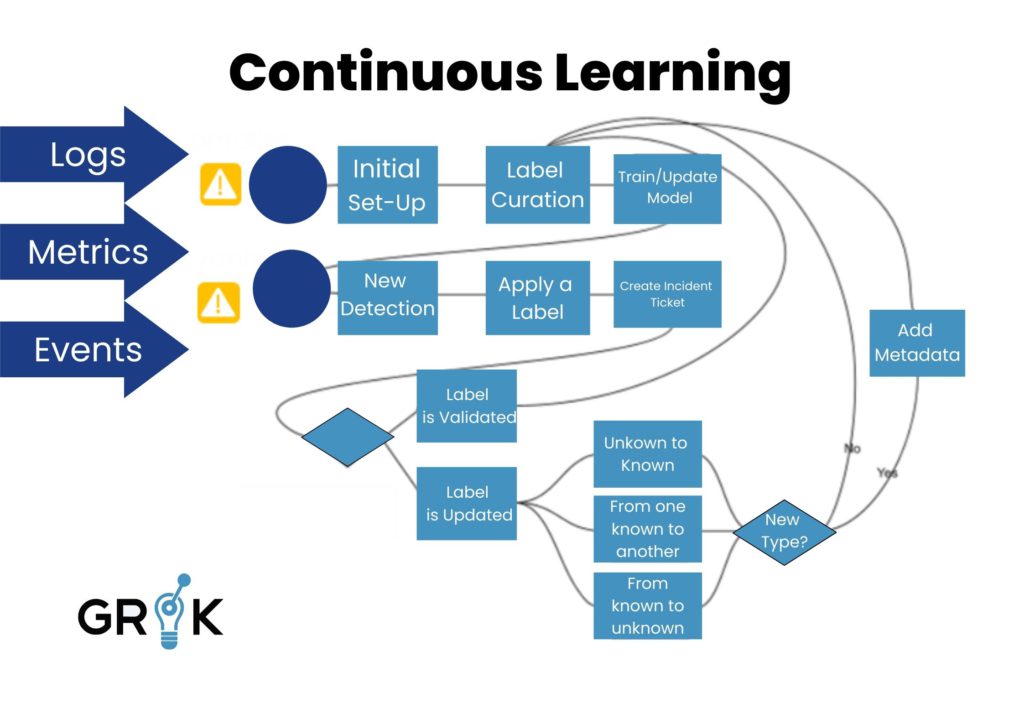
These AIOps 1.0 systems were unable to satisfactorily resolve and usefully interpret monitoring noise because the IT environment was too dynamic and because every individual environment was very different from every other. These challenges demonstrated that relying on codebooks, recipes and other formulations of embedded rules was a trap AIOps innovators needed to avoid. These solutions were limited in the same way that earlier forays into applied AI, like expert systems. The Grok founders focused on using an MCM employing AI and Machine Learning for Incident classification, root cause analysis and prediction.
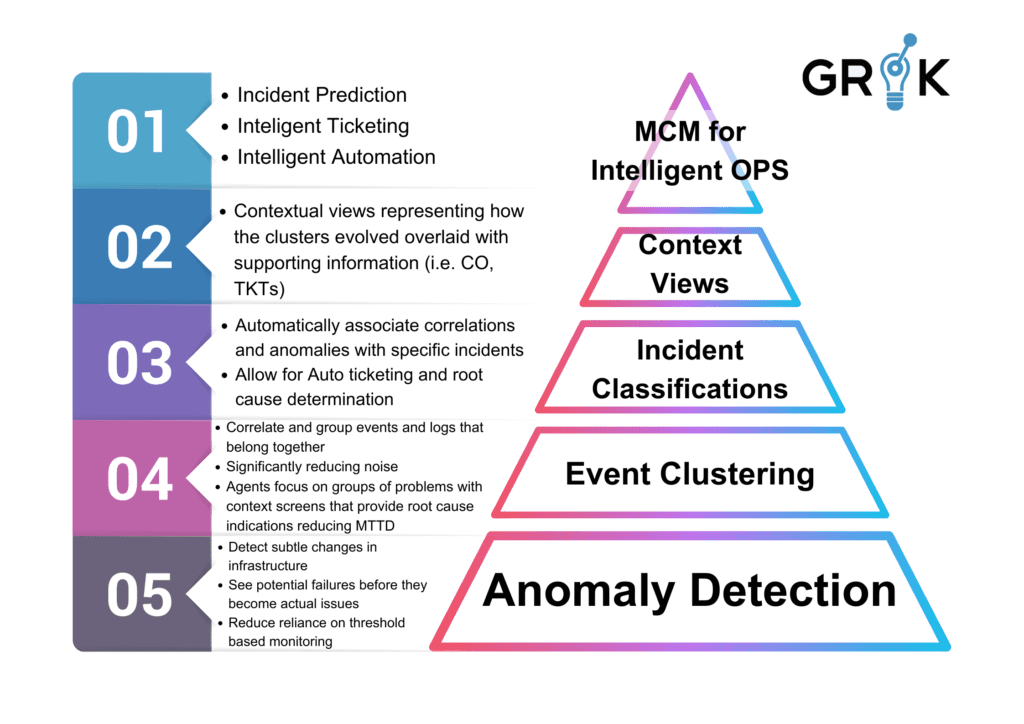
End-users wanted an AI/ML platform that helped them with multiple use cases across the entire ITOps domain, not just a single use case, and Grok delivered. By using a focused MCM purpose-built for this entire domain, Grok self-learns and self-updates as it experiences new information and feedback from humans.
With Grok and its ML early warning capabilities on the organization’s IT team, the team can become lean and nimble, efficient and pro-active, and IT systems in their care can be optimized to perform as the system’s design engineers intended.

Gartner defines AIOps as “Artificial Intelligence for IT Operations”
Grok takes a page from Gartner and combines big data and machine learning to automate IT operations processes, including event correlation, anomaly detection, and causality determination. Grok drives better outcomes across Gartner’s identified categories of Monitoring, Engagement, and Action.
Simply put, Grok is the power of AI and Machine Learning that improves IT operations and processes. Grok supports and fortifies IT teams as they face day-to-day IT events.
Gartner’s framework helps to explain how Grok works. Simply stated, Grok’s AI and Machine Learning can help to achieve the goals of any organization’s Ops Team– to detect and proactively identify any threat or vulnerability as quickly as possible and then to repair the improper function promptly to prevent further complication or event recurrence.
Grok detects unusual system behavior, provides early warning, suppresses noise, categorizes related threats and vulnerabilities, and attributes causes. These behaviors are modeled as analogues to biological counterparts and connected to form the Grok metacognitive model.
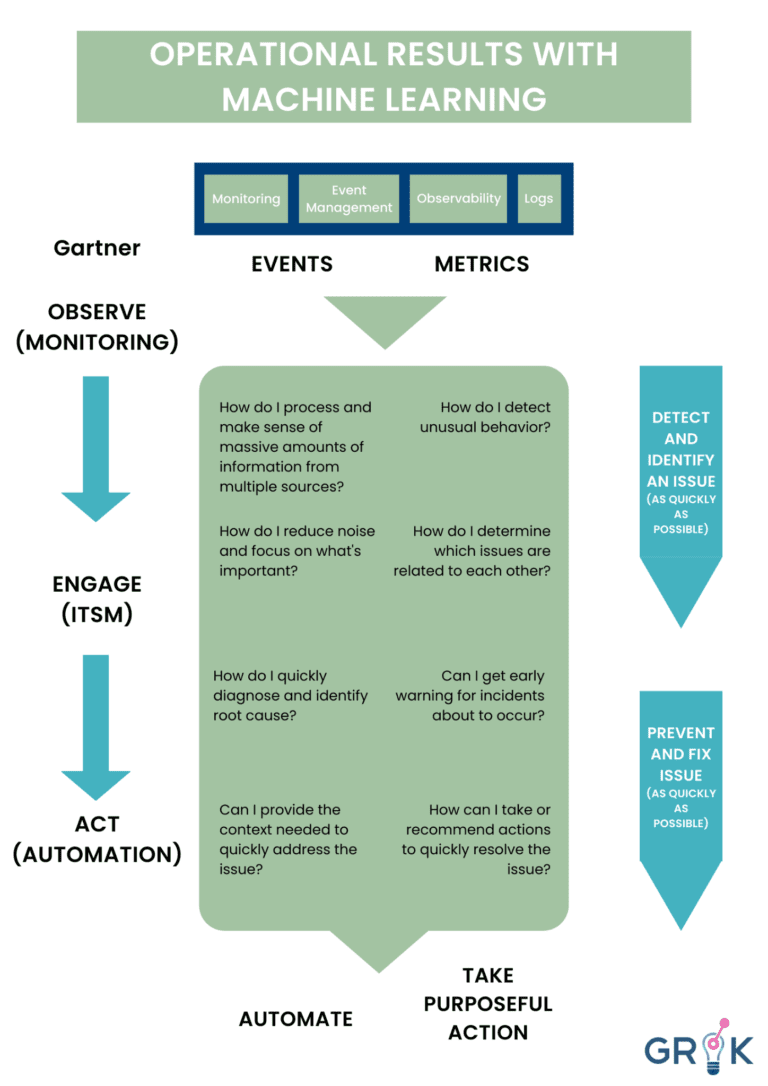
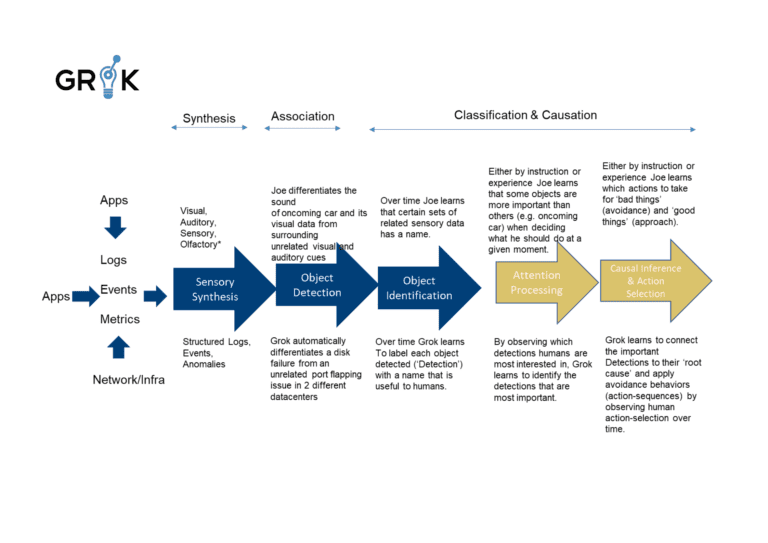
Grok then presents to an organization’s IT team a small, manageable subset of substantive events, threats, or Incidents which can be promptly (and often proactively) and effectively addressed. To accomplish this Grok doesn’t pipe all data into a single LA based circuit. Rather Grok employs a metacognitive model, consisting of multiple LAs at various stages of cognition.
And lastly, Grok can learn from human feedback without any requirement to develop or maintain rules. Grok’s learning is not limited by the ‘implicit’ learning of an individual learning algorithm (LA). The Grok MCM consists of several connected LAs, each designed with its own externalized feedback function, driving updates to each LA and synthesizing knowledge of the domain to the overall MCM. In this way Grok learns about the world by ingesting sensory inputs (logs, events, metrics) but also learns how to behave in the world (action selection and prioritization) by first observing human behavior, taking actions similar to those previously observed, and learning from its mistakes.
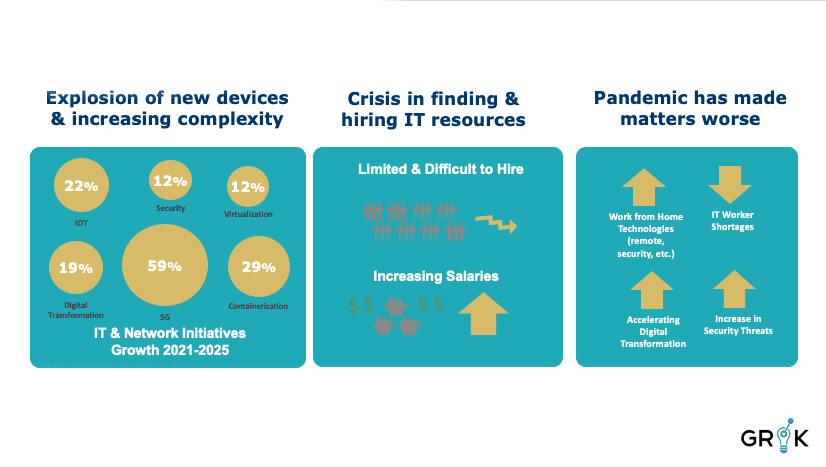
ITOPS and DevOps is in the midst of a surge of innovation. New devices and new systems are appearing at an unprecedented rate. There are many drivers of this phenomenon, from virtualization and containerization of applications and services to the need for improved security and the proliferation of 5G and IOT devices. The interconnectedness and the interdependencies of these technologies also greatly increase systems complexity and therefore increase the sheer volume of things that need to be integrated, monitored, and maintained.
In this environment, Grok is a practical addition to the ITOPS capabilities and architecture of any organization. Grok makes it possible to scale computing resources and allocate IT resources efficiently and effectively.

Grok is superior to all other solutions and to all first-generation AIOps solutions in the marketplace.
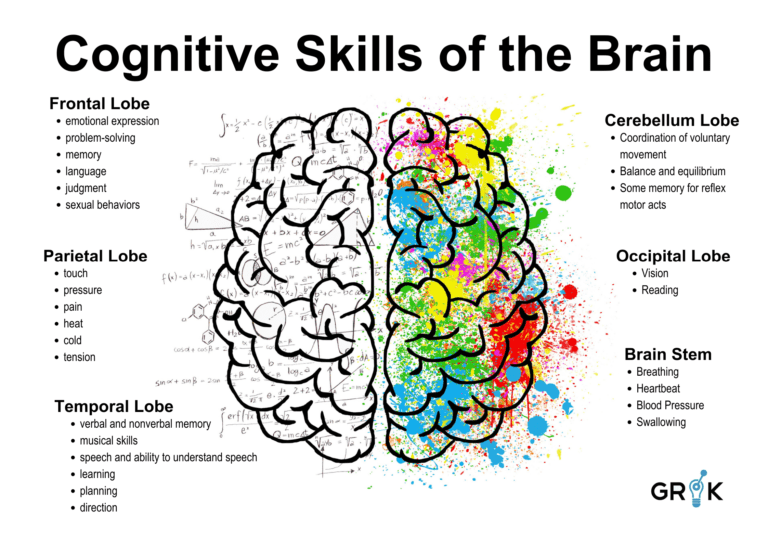
Grok leverages concepts from neurobiology and neuroscience research and organizes its machine learning capabilities around a metacognitive model that is goal-directed, flexible, and self-teaching. Grok uses the term ‘meta’ when describing its cognitive architecture to emphasize the underlying design constraint that it is purpose built for a specific cognitive domain (ie Incident prevention) using neuronal circuits in the brain as analogues. Grok MCM is modeled to include behavioral functions of key brain regions like the neocortex, which is responsible for higher cognitive functions like causal inference, decision making, action selection, and language.
Send video link to:
Grok’s association region performs the critical function of object detection, which involves partitioning the operational data stream such that each partition or group of data is related to a single underlying cause.
Grok’s has evolved its thinking about how best to employ ML and AI for Incident prevention over more than 10 years of continuous research. Grok’s earliest beta was built using an innovative cognitive architecture called HTM for anomaly detection in time series data. This algorithm was inspired by the sparsity of neural data in the Neocortex to produce a very flexible, general purpose anomaly detector. Later, Grok’s representational memory, which is the center of the approach to unsupervised in-stream clustering, captures the complexity of modern IT systems, where object relationships span network layers and business context. The inspiration for the design came from research on the connection between association cortices in the brain and the hypothalamus, the brain region central to memory storage and processing.
Grok will recognize and understand operational data (events, perf, logs, etc.) to make a decision in real time as to how each element of the real-time stream is related to every other element because, unlike the mammalian brain whose attention process data in a manner that is in many ways single-threaded, Grok can learn quickly across multiple threads simultaneously.
Grok will quickly provide results with minimal data sets and will continue automatically to refine and update its understanding of the data stream.
The Grok founders focused on using an MCM employing AI and Machine Learning for Incident classification, root cause analysis and prediction. End-users wanted an AI/ML platform that helped them with multiple use cases across the entire ITOps domain, not just a single use case, and Grok delivered. By using a focused MCM purpose-built for this entire domain, Grok self-learns and self-updates as it experiences new information and feedback from humans..
With Grok and its ML early warning capabilities on the organization’s IT team, the team can become lean and nimble, efficient and pro-active, and IT systems in their care can be optimized to perform as the system’s design engineers intended.
Grok easily integrates with existing monitoring and observability tools.
Grok can also understand and use enrichment data such as incident/ticket information, CMDB information, and change information to build out pertinent models.
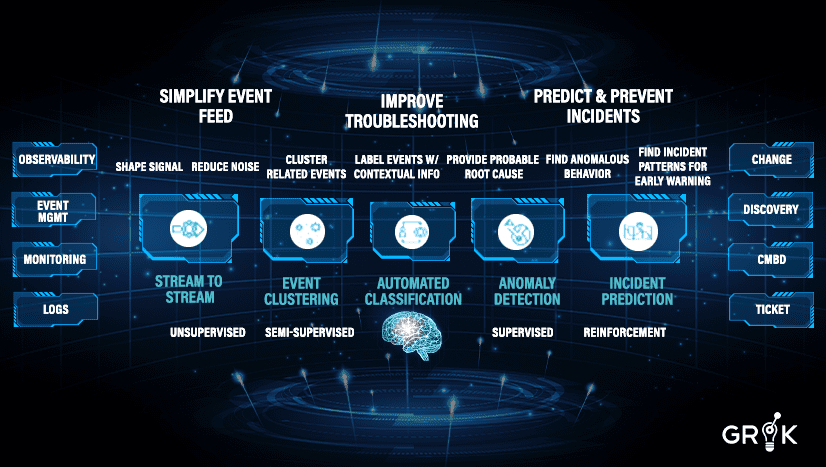
Grok is a holistic set of capabilities that incorporates AI and ML to penetrate monitoring noise and simplify the event feed, and thereby to prevent when possible and improve when necessary the troubleshooting required by the organization’s IT team. Over time Grok learns to proactively analyze existing and emerging patterns and predict incidents before they happen, thus providing early warning and preventative automation.
Grok is broad in functional capability (connectors and integrations) and deep in ML building blocks (families and variations of ML algorithms).These broad and deep capacities, organized in a metacognitive model purpose designed for the task, allows Grok to self-teach and to auto-update in real time.
Grok shapes the monitoring signal with a Stream-to-Stream integration engine. Grok will not only integrate with third-party systems but makes it easy to split incoming operational data streams (events, logs, metrics) and further combine and shape them to build robust pipelines for upstream ML components of the Grok MCM..
Grok processes sensory data through a series of integration circuits, comprised of anomaly detection and semantic clustering LAs, to convert all operational data to a common format, Grok Events. In the brain this function largely takes place in the parietal lobe. Here, Grok performs Anomaly Detection by looking for abnormal behavior in performance data and signaling higher level processing when such abnormal behavior is detected. Grok also performs semantic clustering on semantic or semi-semantic operational data (log streams) to pre-process them for up-stream use.
Grok then performs ‘object detection’ where it groups related and similar logs, downstream events, and metrics (anomalies), all converted to Grok Events, (clustering) by building a self-updating representational memory of all related Grok events and their patterns. This process reduces monitoring noise and offers the organization’s ITOPS team the opportunity to avoid viewing related incidents as disparate entities when they are connected to a common root cause. Grok performs this function without any rules, recipes, or definitions.
Grok next performs ‘object recognition’, an automated classification function which labels and enriches the event clusters (‘Detections’) with meaningful names, root cause, and other info based on prior history and feedback. Grok makes this information seamlessly available to the IT Operations team using an AIOPS interface and more importantly through upstream ticketing integration.
Grok alone provides this level of intelligence, and in so doing moves ITOPS organizations from a reactive posture to a proactive posture..
As Grok learns about the behavior of the underlying systems, it performs Incident Prediction by identifying causal signatures of Detections/Incidents early in their lifecycle that signal an Incident is about to occur. Grok then provides early warning so the organizational IT team can proactively address potential events before they become critical incidents. Moreover, Grok can connect these early causal signals to action sequences and prevent the nascent Incident from manifesting or being observed.
Grok’s capabilities are functions of its MCM, which self-teaches and self-updates and can dynamically adapt to changing and growing environments. The Grok MCM requires only minimal configuration changes over time, since component LAs are updated automatically based on human feedback. For this reason, the Grok MCM doesn’t require the allocation of additional human staff to the existing observability / OSS teams
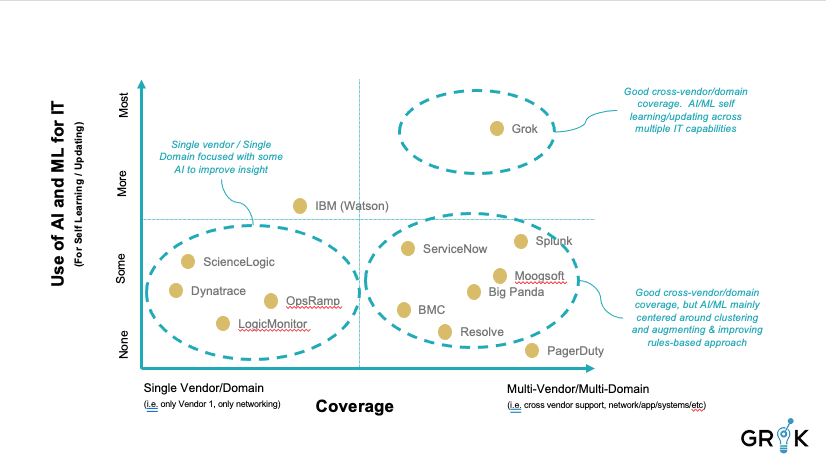
Much money is currently being invested in AI and ML resources by organizations that seek a means to improve IT operations. Two categories of commercial options dominate the contemporary ITOPS scene: 1) rules-based strategy with single vendor/single domain coverage and narrow-purpose bolt-on AI or ML component(s) and 2) AiOps 1.0, first-generation multi-vendor/multi-domain coverage with purpose-built ML component(s) to enhance the use of a rules-based architecture.
The first category of commercial options adopts a rules-based strategy and offer components that bolt-on a particular Learning Algorithm to its existing systems in an attempt to add an intelligence feature for monitoring either a single domain or the proprietary platform’s own stack of events – vendors like ScienceLogic, Dynatrace, LogicMonitor, OpsRamp, and others fit in this category.
Send video link to:
Vendors in this domain typically focus on ‘observability’ as the lynchpin of efficient and effective ITOPS. This siloed approache goes deep in one monitoring a paritular domain but doesn’t allow for learning across various operational data domains, limiting the ability of ITOPS teams to benefit from the underlying ML.. Moreover, applying a single LA to a single operational data stream, say anomaly detection for time series data, may provide some benefit but will not drive a substantial increase in overall efficiency within the ITOPS domain. Anomaly detection on its own will simply drive more inefficiency up through upstream support teams by increasing noise. Any partial approach preserves or expands existing system rigidity (rule-sets) and encourages an inefficient, reactive response posture, rather than a proactive posture in the organization’s ITOPS team.
The second category of commercial options are represented by the pureplay AIOps 1.0 platforms. These offerings are also typically overlay technologies (although some have begun to develop as their own observability components) all built upon a rules-based architecture and using ML to add or augment rules in a traditional rules engine. Ultimately the rule-base is constrained by the complexity of maintaining the existing rule base as the underlying infrastructure changes and evolves.Just how much ML and AI is actually incorporated into the commercial platform varies widely from platform to platform. Vendors may rightly claim their offerings to be AIOps platforms even though they may have a single ML algorithm that monitors only Anomalous Behavior. Others may have multiple LA types (clustering, anomaly detection, classification) but they are deployed as a toolkit, disconnected and not part of a cohesive cognitive model.
Although the options in category two generally have more coverage than those commercial options in category one, these solutions still lack depth in AI/ML technologies. Most of these platforms focus exclusively on clustering and have no anomaly detection capability, no auto classification capability, and no incident prediction capability. Lacking these functional domains, and Grok’s overall metacognitive model, they tend to preserve system noise and process rigidity (rule-sets), reinforcing an inefficient, reactive response posture, rather than an efficient and proactive posture in the organization’s ITOPS team.

To understand why these approaches have failed, even though they may incorporate some learning algorithms in their repertoire, consider the task of teaching a cow to play a video game. If we design an appropriate interface, conceivably they could learn the rules of the game and develop the skills to play most any game. However, while every cow has a brain composed of complex neural circuitry, including associative centers, sensory processing etc., their neural architecture is lacking in some essential elements required for this domain of behavior. For example, lower mammals lack executive function circuitry required for planning and sustained attention. One might teach a cow a few rules with simple operations, perhaps stomping on a pad to turn the game on, but the behavioral domain is too complex to navigate with simplistic rule-sets. Like many observability platforms and AIOPS 1.0 solutions, the cow lacks the neural architecture for this domain.
Grok: Grok, by contrast, represents AIOps 2.0, a new no-rules approach to AIOps. Grok is an AI-centric platform that employs AI/ML for many uses and in support of many capabilities, organized according to the Grok MCM, that is much more coherent, effective, and fit for purpose. Rules-based platforms emphasize small AI/ML bolt-on features or those with narrow-function ML enhancements typical of AIOps 1.0. fall short in delivering significant and lasting improvements to ITOPS organizations over time.
Because Grok employs LAs within each AI/ML domain (anomaly detection, clustering, classification) and organized within a cohesive and integrated metacognitive architecture, the platform has more foundational capabilities than other commercial options currently available. And Grok is designed to work and deliver value rapidly with little supervision. Grok offers depth at each layer of the problem– monitoring/ingestion and filtering/synthesis, anomaly detection, automated log parsing, event clustering, classification, early warning, root cause identification,pattern recognition and event prediction– all simultaneously fortified and enhanced by Grok’s MCM through self-monitoring, self-teaching, external reinforcement, and self-updating capabilities.
Grok optimizes allocation of the ITOPS and Dev team’s staff and resources to preserve and protect the associated systems and services over time, without over-staffing level 1 and level 2 support functions
Send video link to:
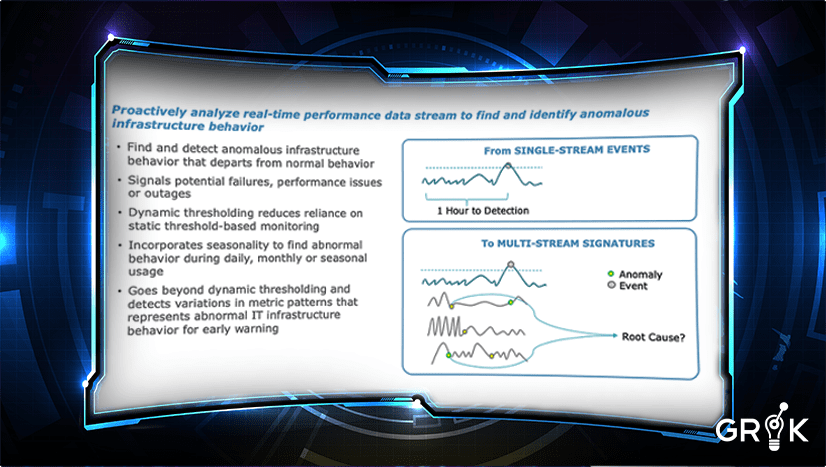
Grok’s anomaly detection provides this early signal that enriches detections and event clusters and provides improved root cause identification to the organization’s IT support team.
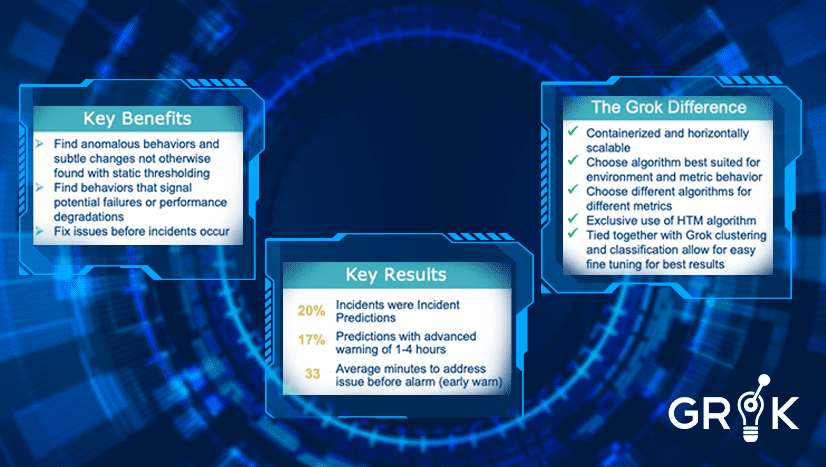
Grok’s anomaly detection helps to improve the timeliness of predictions. Grok will learn that certain anomalous behaviors tend to occur concurrently with specific minor events before a critical event emerges. Grok’s self-teaching and self-updating features make earlier and more accurate incident predictions possible.
Grok’s anomaly detection capability is based on Numenta’s groundbreaking research into the operation of the human brain. Grok’s anomaly detection algorithms include Numenta’s HTM algorithm, as well as many more, including Robust, Random Cut Forests, N-Sigma, and KNN. Grok automatically evaluates the performance of anomaly detection within the MCM and selects the optimal algorithm for a given environment. Grok’s unique flexibility in this regard makes it superior to anomaly detection options available in the industry today.
Grok does not require selection of each and every metric against which anomaly detection is to be performed. Instead, Grok will accept and interpret a large stream of time series or metric data and will automatically build individual AD models for each metric and immediately begin the process of baselining. Parameters like ‘resolution’ are automatically adjusted based on performance as the behavior of particular metric streams are observed.
Send video link to:
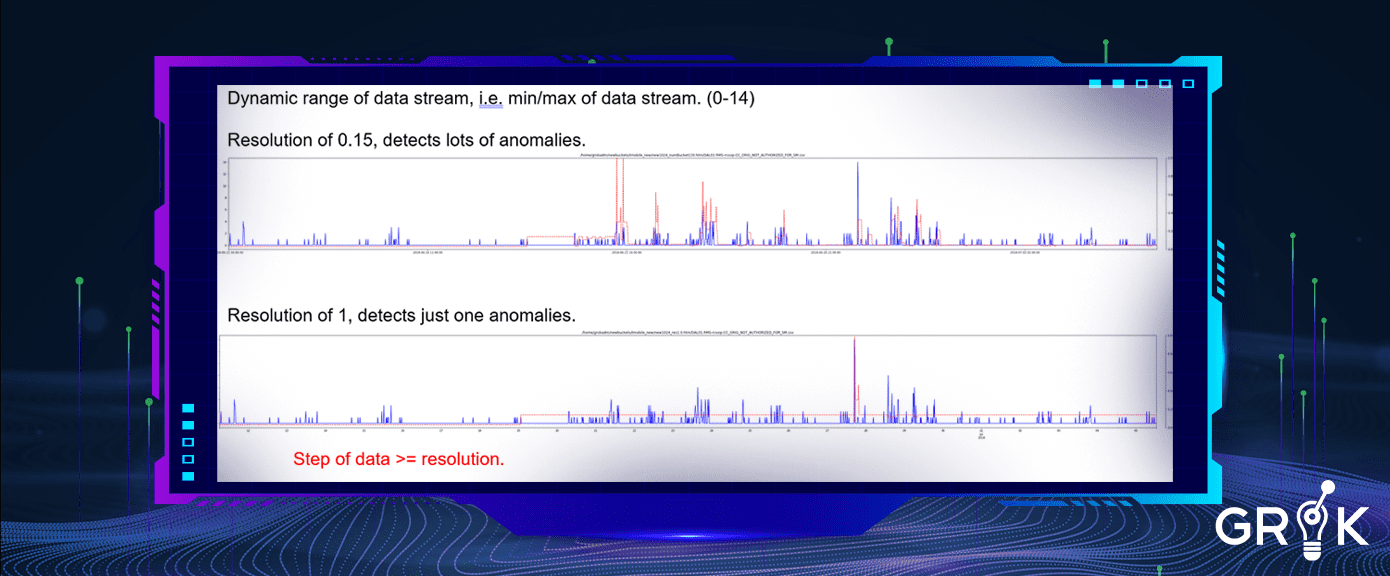

Grok does not require selection of each and every metric against which anomaly detection is to be performed. Instead, Grok will accept and interpret a large stream of time series or metric data and will automatically build individual AD models for each metric and immediately begin the process of baselining. Parameters like ‘resolution’ are automatically adjusted based on performance as the behavior of particular metric streams are observed.
Send video link to:

Grok provides a versatile selection of anomaly detection algorithms that can be used together or individually, depending upon the behavior and characteristics of an organization’s IT environment. Grok’s anomaly detection algorithms are individualized and are not a-one-size-fits-all proposition. Some organizational environments have high volumes of metric data, low polling times (1 min) and Grok needs to learn from months and months of history. Such organizations require specific types of algorithms compared to environments where polling times may be longer (i.e. 15 minutes) and volumes lower. Light-weight ADs like KNN are available for rapid and light-weight deployment requirements. Advanced, modern time-series AD algorithms like Robust random cut forests (RRCF) are also available for environments or portions of a particular environment that require more than spacial anomaly detection.
Anomaly detection matters. The creation and introduction of fixed thresholds into telemetry data takes time and resources and produces small gains for the effort. For example, 90% cpu may be bad for some services and satisfactory for others. Also, if all operational data is processed as a threshold driven event, lots of useful information gets held back from upstream processing.
By applying anomaly detection to our metric data, we have access to more information about the state of the overall systems. Thresholds are hard to pin down and manage- sometimes anomalies are easier; in many ways they are self-managed. Anomalies enrich detections (clusters of Grok events) for improved troubleshooting. Anomalies give Grok a chance to detect Incidents earlier in their lifecycle. In that way, Anomalies give Grok a better chance of determining the root cause of each Incident.
Send video link to:

In order to make use of the various logs within enterprise IT organization, the logs must be parsed and centrally stored. Parsing refers to various techniques for extracting and tokenizing information from individual log files using rules-based templates. For the two simple Openstack log entries below, the task of parsing is illustrated on the left. One of the challenges with parsing is that semantic information, certain words with special meaning, as templates are generalized. The primary challenge of course is that building and maintaining a vast library of rules based templates requires significant resources. Parsing in this way makes sense if the goal is ‘analytics’, ie analyzing the data for human consumption.
However, the use of parsing should be limited with respect to driving log data into an AIOPS engine. Machine learning techniques can separate, sort, and organize the incoming log messages without the need for extensive parsing rules.
Send video link to:

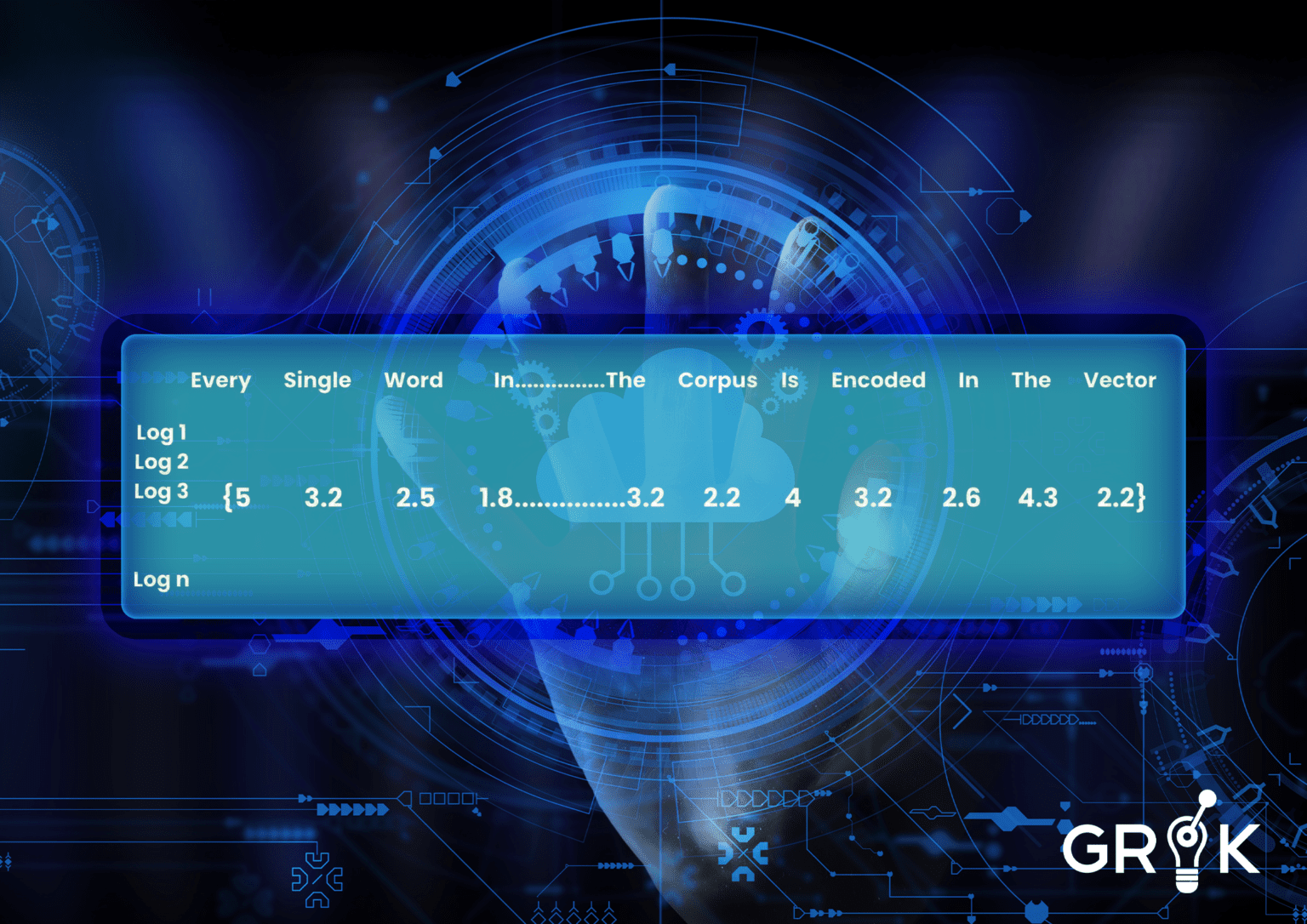
Grok performs semantic clustering for logs as they enter the Grok MCM in three easy steps. First, Grok either collects a sample or is provided a historical sample of logs. ML models need input to be numeric- so the first task is to convert all message information to a ‘vector of words’ numeric representation (called embedding). For ML models to understand the relative importance of different words we choose an embedding strategy that characterizes importance based on how often a word occurs throughout the corpus (ie all historical logs). If the word ‘under’ appears often in every log it will have a small weight.
Send video link to:
In order to make sure common words like ‘at’ or ‘the’ do not confuse the model, each word vector is weighted by its relative frequency in the corpus using the term frequency inverse document frequency (TFIDF) method.
Send video link to:

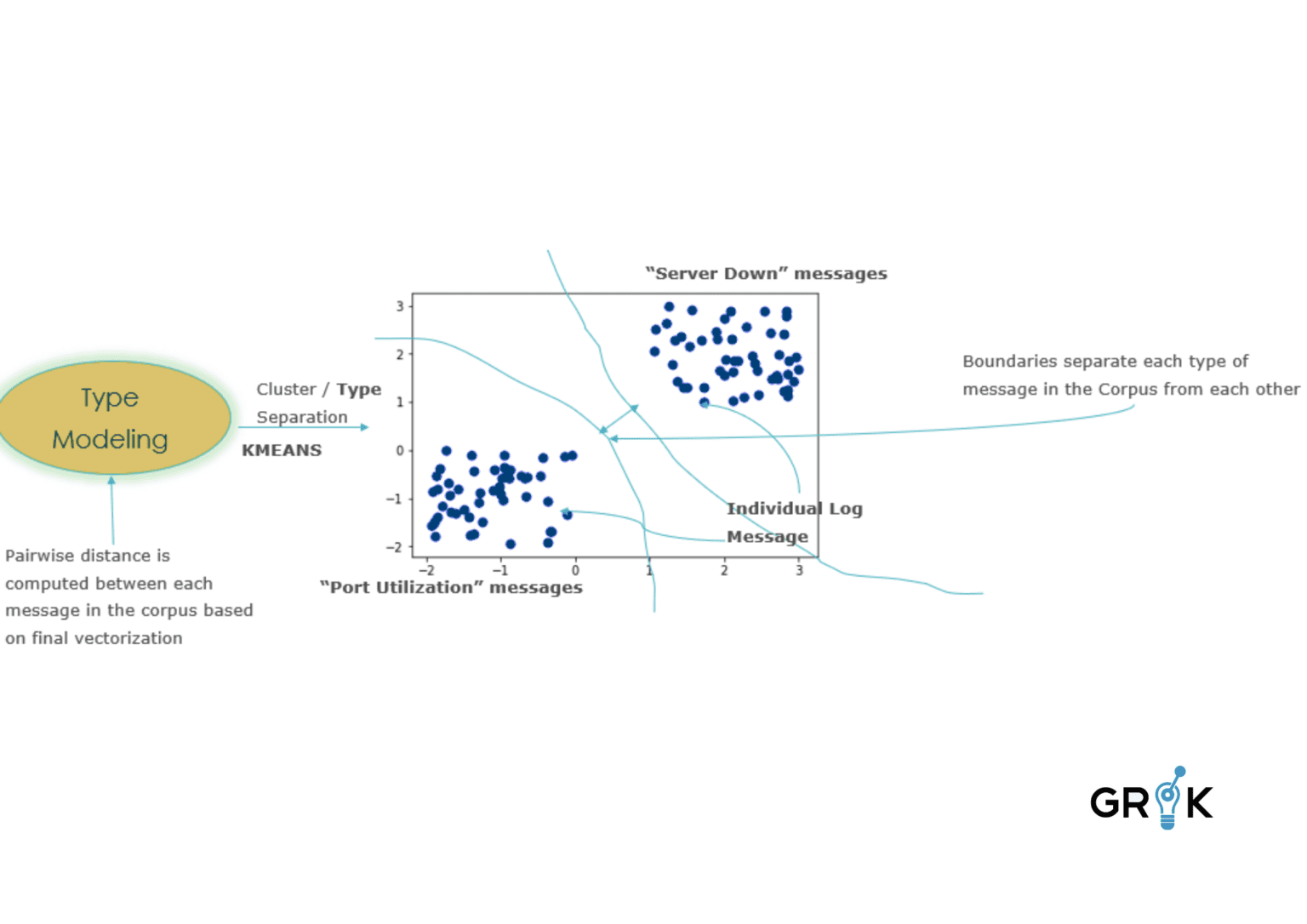
The next step after each log file in the sample is converted to a numeric ‘word vector’, Grok employs a K-Means model to train a model to differentiate log entries by types separated in the training data. The goal is for grok to the separate individual log files into groups based on how similar they are with respect to their embeddings.
Send video link to:
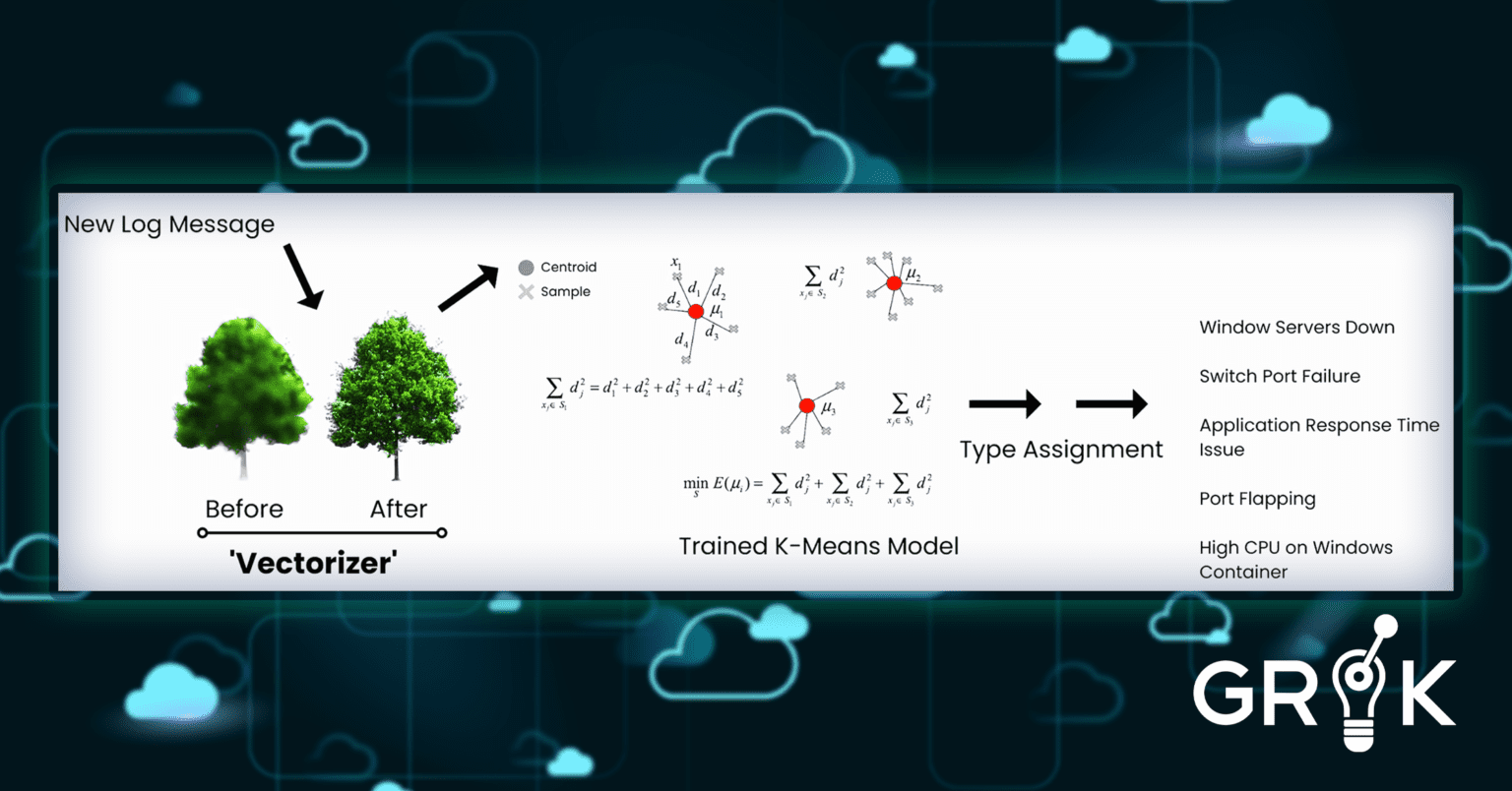
The final step is for Grok to activate the model and apply its label to each incoming log message.
Send video link to:
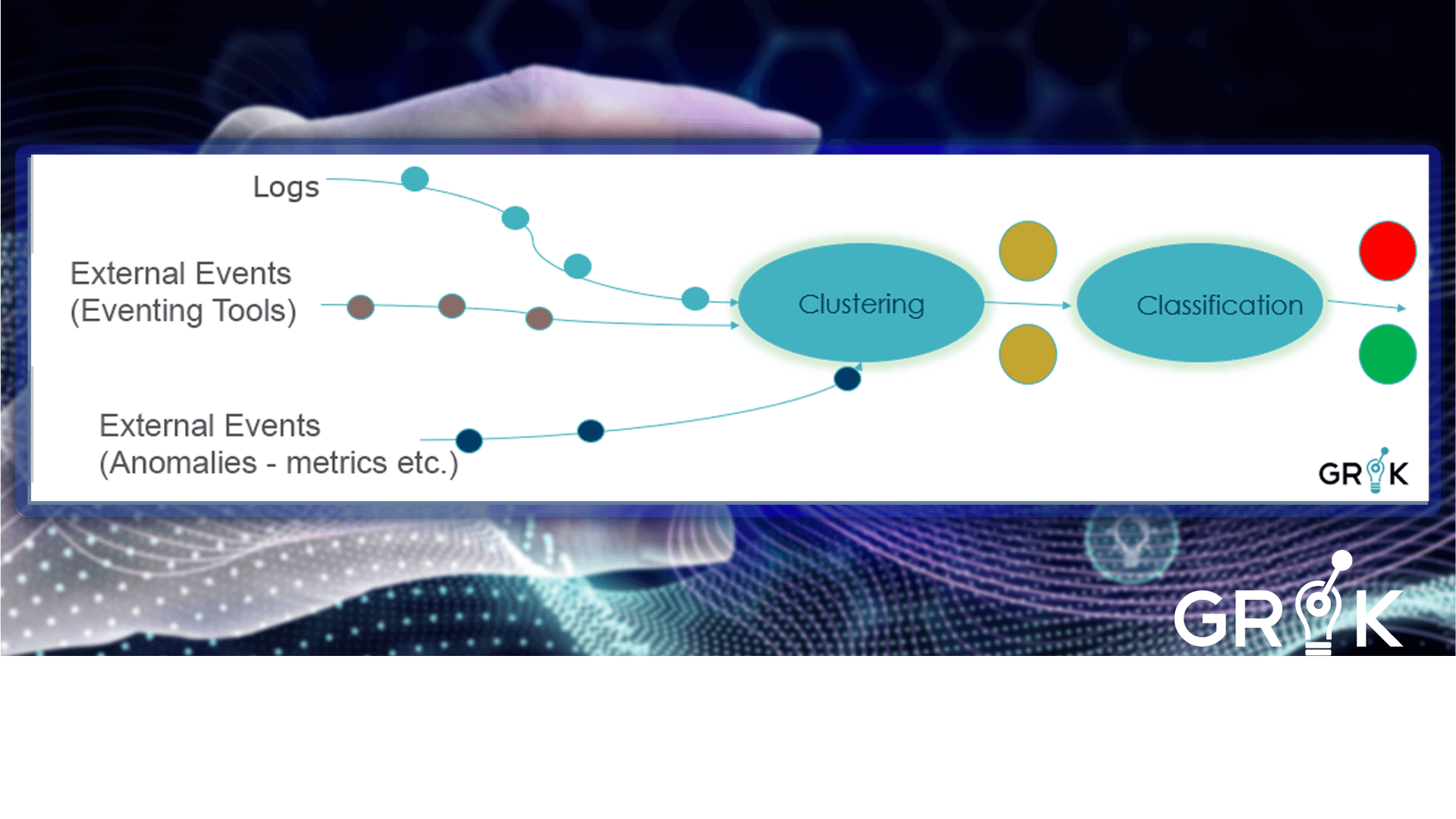
Grok semantic clustering for logs is important because without it, the only method of making use of the logs for proactive operational support is first parsing and then eventizing the logs for IT operators to view and investigate.
With Grok, with minimal or no parsing we can systematiclly generate Grok events with node, timestamp, and message type. Grok can then cluster the generated Grok event with other events and anomaly data, learn associations, and identify early warning signals for Incidents.
Send video link to:
Dynamic and automated (unsupervised) event clustering groups all related events together in real-time for possible ITOPS action. Before Grok clustering algorithms can be applied to an incoming Grok event stream, Grok must first observe temporal and semantic relationships across a set of historical events, either captured in the stream or provided before launch. While observing this initial stream of events, Grok constructs an understanding of the relatedness of individual events. Grok generates the memory in the form of a series of matrices that store the pair-wise relatedness of each event.
Send video link to:
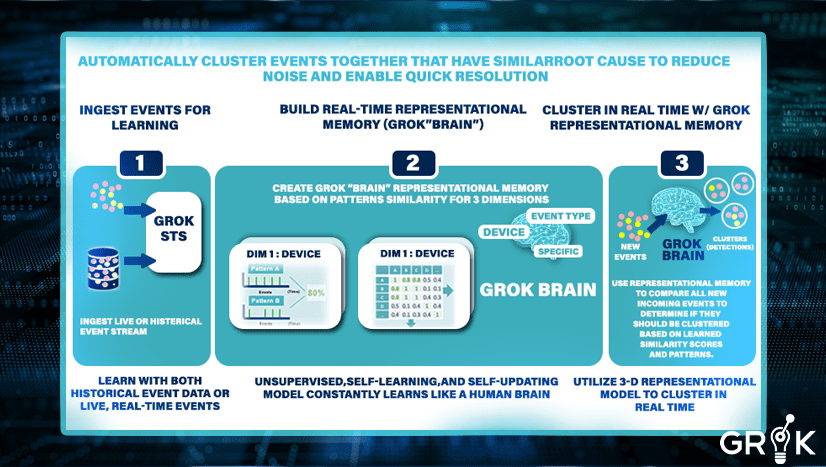
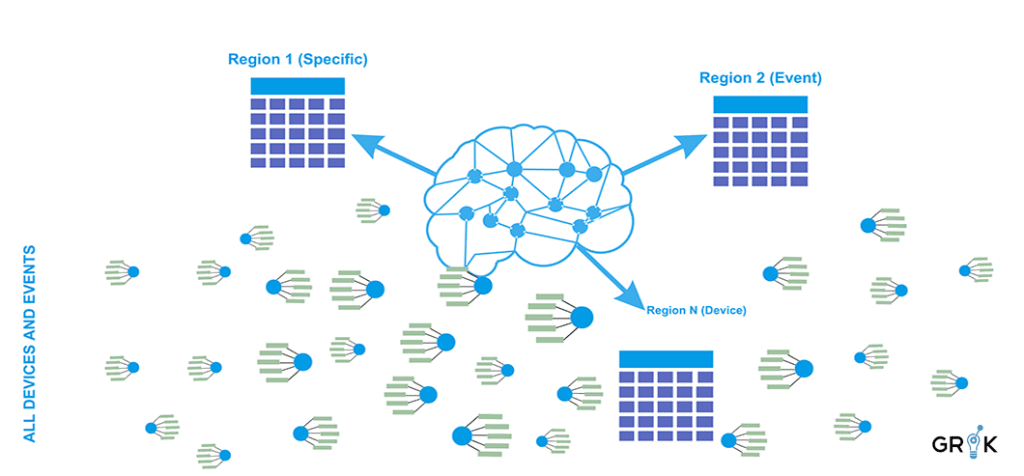
To construct this model, the event stream is characterized across multiple dimensions– the particular characterization depends on the nature of the infrastructure but typically includes a specifc dimension EventSource/Node (‘host 123’) + Event Type (‘cpu high’ etc.), a node dimension, and an event ‘type’ dimension– Each characterization of the event stream generates a region in the Grok Representational Memory.
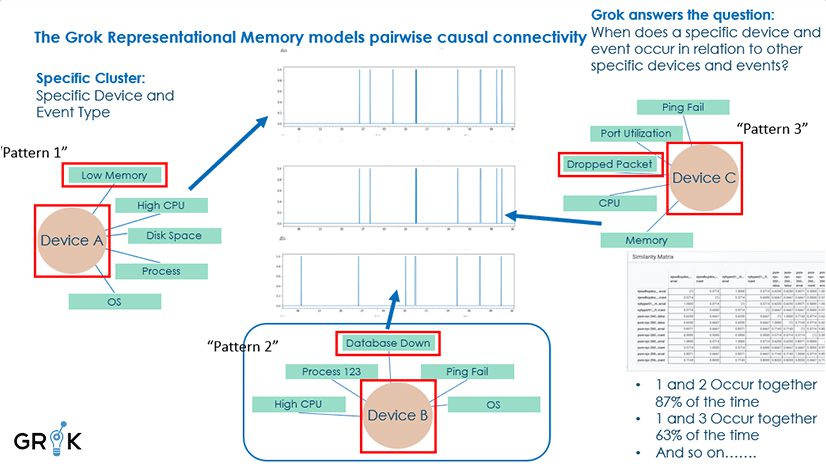
In the analysis of a single dimension, event patterns would be based on each unique value in that dimension. For instance if “Device” is the dimension, then the event patterns for Device A, Device B, Device C, etc. would be compared and then the event firing patterns would be compared to discover similarities. In the case cited in the schematic below, devices A and B were compared and an 87% pattern of similarity was recorded.
Send video link to:
This analysis would be performed at scale across all an organization’s unique devices and device types – perhaps tens or hundreds of thousands– and a pairwise comparison (meaning comparing each unique value pattern to each other) would be executed to create what is called a “distance matrix.” This would show the similarity of every device pattern with every other.
The same analysis then would be repeated across the other dimensions of event type and then event type+device, and any bespoke dimensions constructed as needed. The resulting distance matrices – one for each dimension– when taken together comprise the full Representational Memory. The Representational Memory represents Grok’s unique and organization-specific understanding of the causal connectivity of all devices, applications, etc. across the enterprise..
Grok thenuses, in real time, this continuously evolving representational memory to continually self-refine its own understanding of relatedness–The Representational Memory is supplied to the Grok clustering algorithms to decide how to group events together as they flow through the event stream. All results from monitoring and filtering, anomaly detection, log typing, flow through this process and feed upstream components of the Grok MCM such asclassification , early warning, cause identification, pattern recognition and Incident prediction
While the Grok MCM is not limited to a particular clustering algorithm, heirarchical clustering is typically used. Hierarchical clustering has useful characteristics including the ability to model non-parametric (non-linear) relationships in high-dimensional spaces (many nodes, connected across a complex graph structure with many event types).
Send video link to:
Grok’s unique ability to leverage semantic information in the events across multiple dimensions, together with temporal information results in the best possible choice for partitioning the event stream into groups. This happens dynamically; as changes in the behavior of events are observed, the knowledge of the behavior is updated and grouping choices are modified. This happens with now rules and no maintenance tasks over time.
Send video link to:
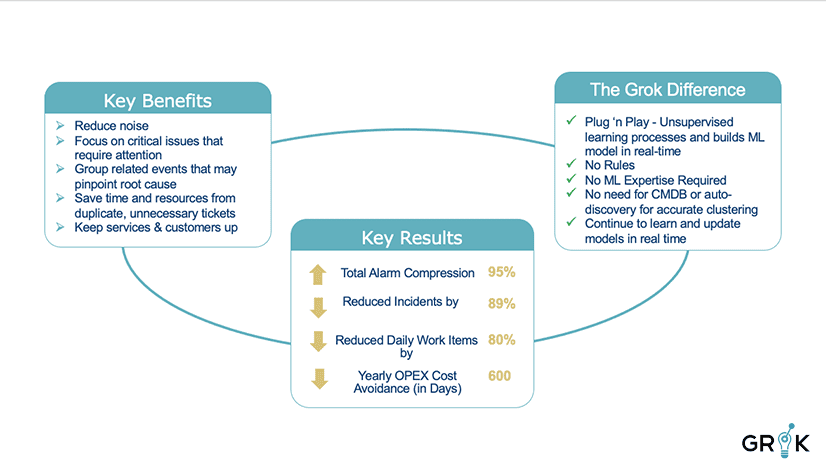
Event clustering reduces monitoring noise. Minimizing noise results in significant reductions in both alarm and incident volumes. Minimizing alarm and incident volumes results in reductions in overlapping activity from ops to customer care to service delivery. Minimizing overlapping activity conserves resources and optimizes all systems and services to the benefit of the organization’s goals.
Most importantly, in order to use ML to identify what is happening, the sensory data must be organized by ‘object’, much like a brain requires an ‘object detection’ neural circuitry preceding ‘object identification’ circuitry. But basing this ‘object detection’ feature on an ‘Expert System’ type approach embedded with rules doesn’t work and it doesn’t scale.
Send video link to:
Network dynamics are too complex to model effectively with a rules-centric strategy. Therefore, the goal of Grok clustering (correlation) is to base the bulk of decision making (when determining if 2 events should be grouped together) in the hands of a learning algorithm, or series of learning algorithms. In this way, the models learn over time without human engagement, but are able to benefit from human feedback. One way to think about this strategy in contradistinction to a rules-based strategy is that of the difference between a mechanical automata from the 1700s, designed to operate in precise combinations of movements, versus the Boston Dynamics robotic dog that can learn new behaviors, such as to walk, from scratch. If the environment changes, i.e. we add a stair-step to it’s path, a rule-based dog will no longer function. But a learning dog will fail, and probably fail again, but eventually learn to function in the new environment.
The benefits to this approach are significant. Significant and speedy compression of event streams. Very little work is required to start effective grouping decisions. No prior knowledge of network or service connectivity is required to see high quality grouping. The system learns dynamically, automatically with each new observation. Humans can provide feedback directly into the system to interactively modify behavior over time. Heuristics (rules) can still be added to supplement and enhance the AI-centric output (Topology-based; service based, Tribal knowledge), without negatively impacting the underlying mechanics of the cognitive workflow.
Send video link to:
Grok generates features from Detections that reflect the nature of the underlying cause. Similar detections are labeled in the same way with relevant metadata such as Name (Port Flapping on Switch), Root cause, Knowledge Article, etc. Grok learns each pattern and identifies incidents early in their lifecycle.
We can think of each detection as belonging to a family of Incident Types that are connected to the same family of underlying causes with similar service impacts, depending on how long they last before remediation action is taken. The goal of incident detection for event data is to identify, for each unique Detection, what is the underlying cause and the best fix action. The earlier in the evolution of the Detection (it may evolve over several hours) we can surface the likely underlying causes and suggested fix actions, the more efficiently the issue can be fixed. The steps to incident detection are as follows: (1) identify a training period with historical events already grouped into detections, (2) calculate event type embeddings for each detection, (3) apply secondary clustering on the detections to ‘jump start’ the detection type labeling process, (4) curate the generated detection type labels, (5) enrich selected/important detection types with initial metadata, (6) connect to incident management workflow for in-process supervision.
Send video link to:
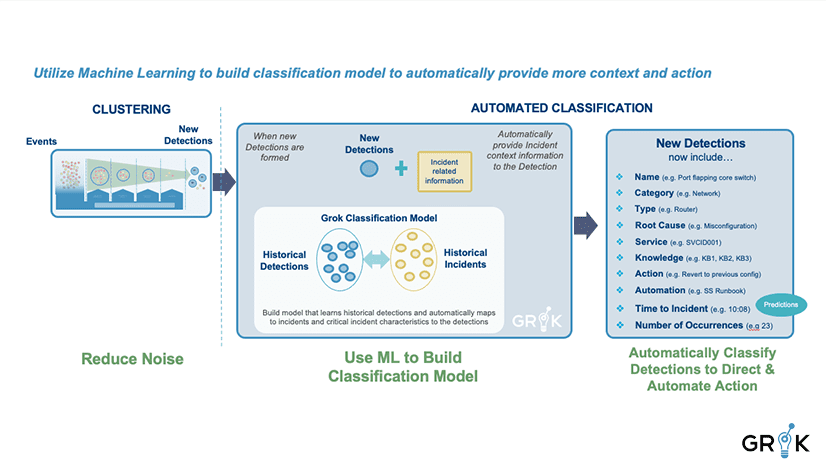
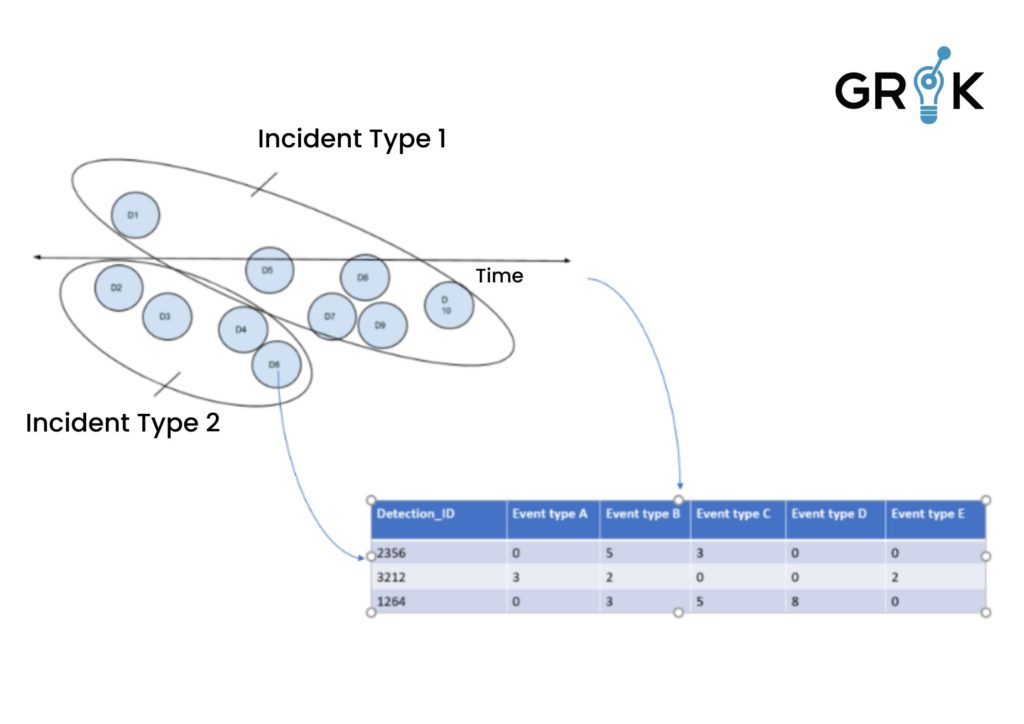
Each occurance of a Detection (group of events with the same underlying cause) produces an entry in the training set , along with its feature vector, which is the count of events of each type within the detection. And each label corresponds to an entry in the DetectionType table with appropriate metadata. Detections are labeled as they form and confidence grows as the detection evolves.
Send video link to:
The design for the classification portion of the Grok MCM has direct analogues in an organic brain (object identification, attention processing, causal inference, and action selection). While the Grok MCM is not limited to a particular Learning Algorithm for classification, a tree-based classification algorithm is typically employed. Grok then trains and deploys a multi-class classification model based on the curated training data. The labels that are under-represented in the training data (minor class labels) are pruned or removed. Grok automatically employs cross-validation to tune available hyper-parameters and selects an optimal model. Choices of underlying classification algorithms include Random Forests, Boosting Algos ( Lightgbm and xgboost), etc. Any of these can be used or a user can deploy their own classification algorithm- the out of the box MCM is deployed with Random Forest based classification.
Send video link to:
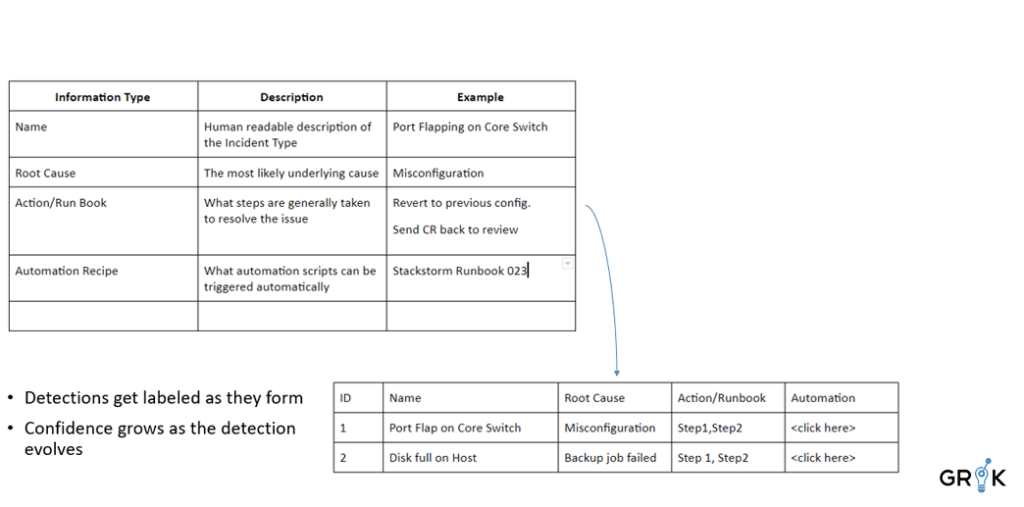
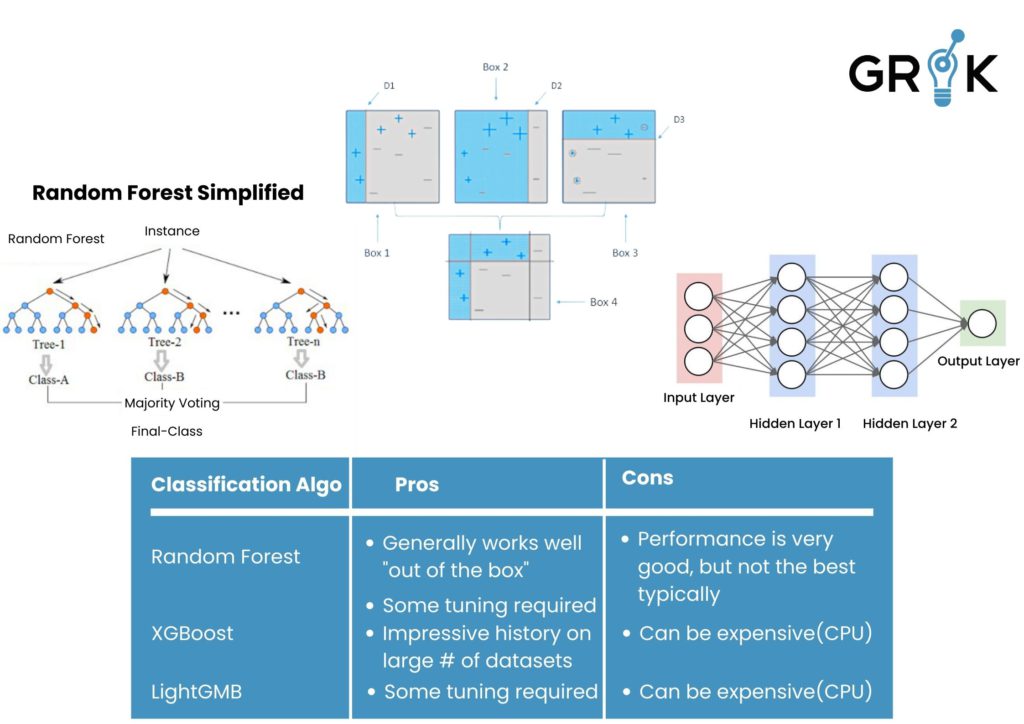
Models are continuously evaluated for performance based on observation of upstream ticket resolution.
Each choice of model involves a different set of hyper-parameters, each combination is evaluated to determine the optimal model update.
Send video link to:
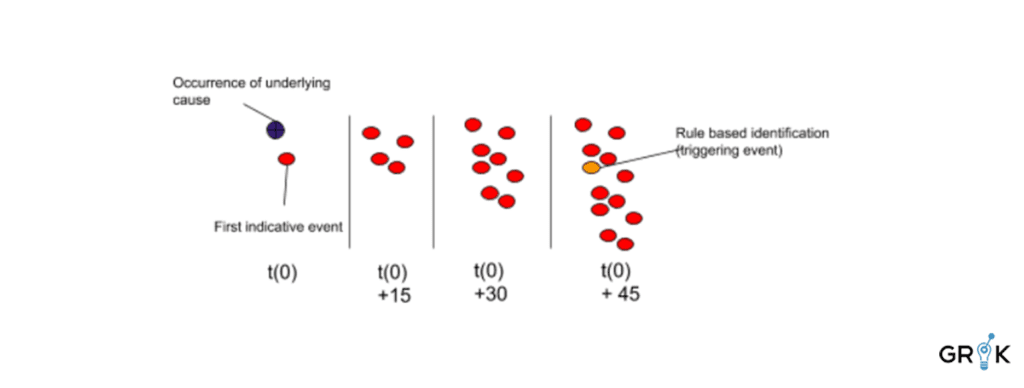
Grok’s goal is to detect the Incident Type as early in the Incident lifecycle as possible. The morphology of the detection that indicates a particular Incident of a particular type may evolve slowly or rapidly. Consider the case below where existing rule based triggers may surface the Incident of Type 𝝰 more than 45 minutes after the underlying cause occurred. These temporal ‘snapshots’ of a detection are encoded in the feature-space so that Grok can identify how a particular Detection, especially those that will ultimately give rise to an incident, looks at various stages of its evolution.
Send video link to:
The final step is to connect Grok to existing Incident Management workflows so that Grok can continue to learn. As Grok identifies a detection as a particular Type, an Incident is created in the external Incident Management system. If the label is not changed after the incident is created, Grok will treat that detection as correctly labeled and include it in the next round of supervised training. If the label is changed to a different incident type, then Grok will treat that detection as labeled with the updated incident type in the next round of supervised training.
Send video link to:
But when we proceed from the lower levels to higher level learning- the classification tasks that I talked about earlier, our goal shifts from noise reduction to early detection and intelligently routing each Incident. By using historical Incident data we can provide Grok with an immediate set of labels from which Grok can start moving up the Incident detection lifecycle. Grok then learns from each Incident it detects- if Grok identified the Incident correctly, say as a routing issue, then that sample is fed back to Grok to be used for training the next version of the classification model. If Grok misidentified the Incident, ie it was really a switching issue, then as that ticket is routed through the remediation process, it will be updated with the correct labels. Grok will then observe the updated labels and incorporate that information into the next version of the classification model. In this way, Grok will continuously learn how to route each general class of Incident (ie a file system full issue) based on how it manifests on the network. Because a file system filling up might require a very different Run Book and Automation workflow depending on what application it supports.
Grok’s ‘world’ consists of optimizing network and systems performance and Grok behaves in the world (action selection and prioritization) by first observing human behavior, taking actions similar to those previously observed, and learning from its mistakes.
Send video link to:
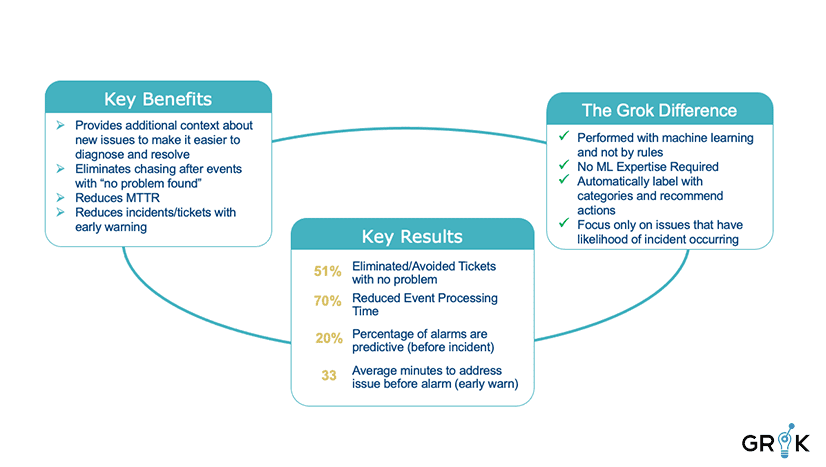
Automated classification matters. Grok penetrates monitoring noise to differentiate and identify situations that require action. Grok’s capabilities eliminate significant and unnecessary expenditure of effort and resources by the IT team that would otherwise lead to a “no trouble found” result. Grok allows the organization practically and economically to focus its IT resources on solving problems that actually threaten systems and services.
Send video link to:
Much like we can’t teach a cow to play Minecraft, without automated classification deployed within a connected cognitive model linked to downstream sensory processing, we can’t teach an AI to identify, prioritize, and ultimately prevent incidents.
Conclusion: Grok is an AIOPS platform that utilizes each required domain of ML (anomaly detection, clustering, and classification) organized by a domain specific cognitive model, a meta cognitive model, that learns from log streams, event streams, and time series data streams, together with their effect on performance of the upstream services as captured in incident records etc. The MCM processes the information in a biologically inspired fashion. Each component of the MCM architecture is inspired by biological analogues, but tailored to the specific intended domain. In this way, Grok avoids the trap of ‘Expert Systems’ and all their rules-based derivatives. With Grok, Grok customers are not using AI/ML to build better rules, they are NOT building rules to teach AI/ML, rather they are creating an AI that continuously learns, adapts, and improves based on observed behavior.
Send video link to: