Unsupervised learning is one of the machine learning categories that doesn’t need the supervision of models. A learning algorithm is used to discover undiscovered patterns in unlabeled data sets in unsupervised machine learning. Unlike supervised machine learning which employs human-labeled data, unsupervised learning algorithms utilize unstructured data categorized based on patterns and similarities.
Unsupervised machine learning provides algorithms that improve data grouping and investigation. As an essential part of machine learning, it plays a role in well-defined network models where several analysts would rather use unsupervised learning in network traffic analysis (NTA). This is due to frequent changes in data and the insufficiency of labels. Unsupervised learning can analyze complicated data to create less relevant features where the model can be simplified by omitting these features that have negligible effects on important insights.
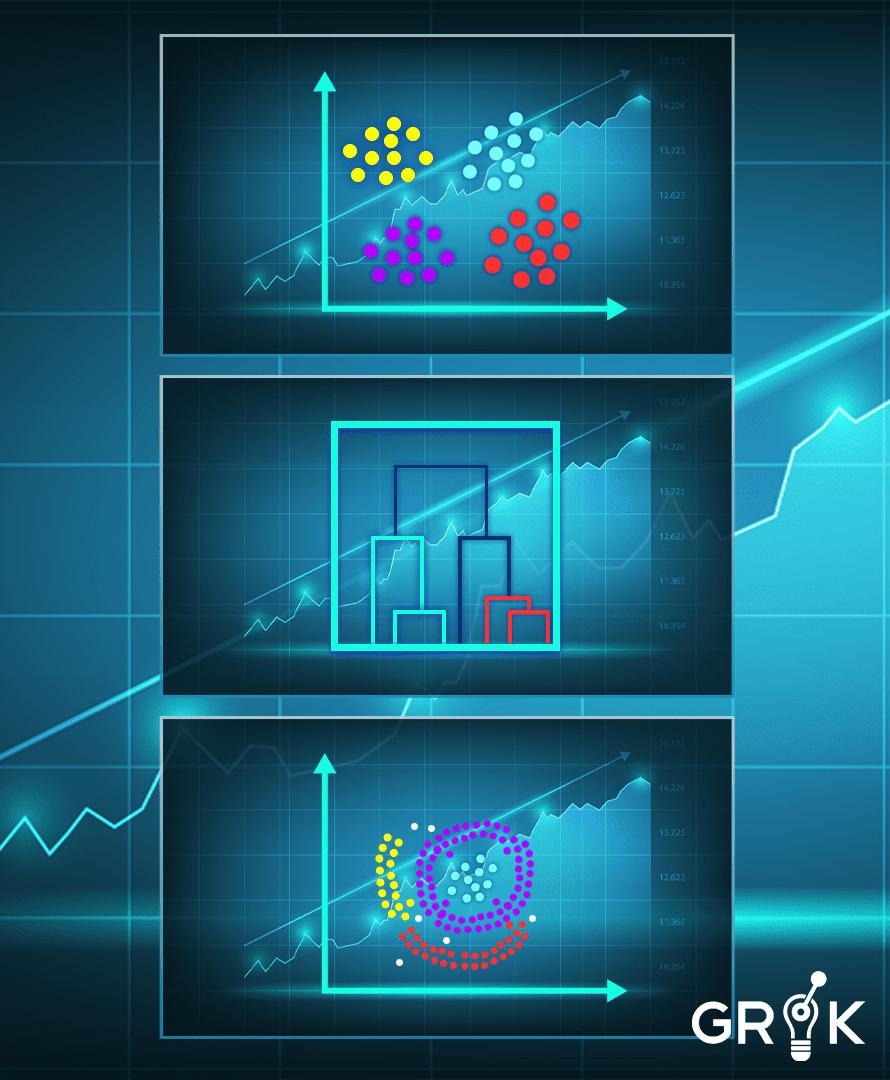
Clustering is one of the approaches to unsupervised learning that groups data based on its similarities. It is the process of splitting up uncategorized data into the same groups or clusters to ensure that similar data points are determined and organized. Through clustering, unique entities’ attributes can be easily characterized. In doing so, clusters can help users sort data and explore certain groups.
The primary use of clustering in machine learning is to extract valuable inferences from many unstructured data sets.
Working with large amounts of data that are not structured makes it logical and necessary to organize that data in ways that make it useful. Clustering does that.
Clustering and classification allow an inclusive overview of important data. And allow users to form actionable conclusions before going deeper into a nuts-and-bolts analysis.
Clustering is a significant component of machine learning, and its importance is indispensable in providing better machine learning techniques.
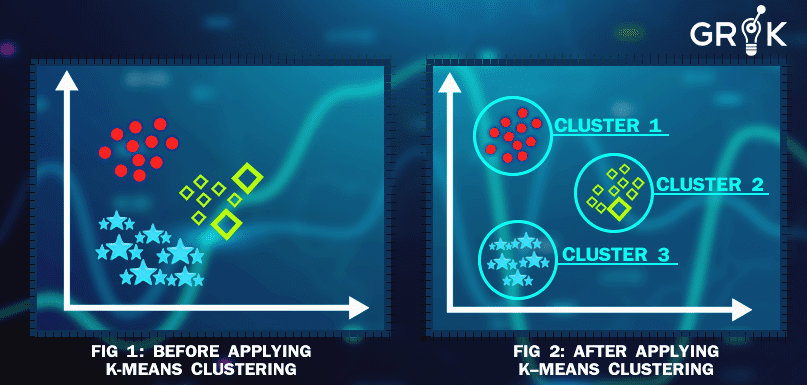
Each group is referred to as a cluster with data points that have high and low similarity with data points in other groups (clusters). In short, data points in the same groups should have similar features to each other compared to the data points of other clusters.
Clustering is commonly used for statistical data analysis in many fields. It aims to divide a set of data points such that similar items are grouped in the same cluster while different data points fall into different clusters. Through clustering and classification, users can form some logical conclusions based on broad generalizations of the data. This is before performing a deeper analysis. As an important aspect of machine learning, clustering is highly essential in delivering better machine learning strategies.
Using clustering algorithms is key in the identification of natural clusters and in processing of data.
Clustering is most valuable when working with large, unstructured data sets. Clustering streamlines work because it can quickly process a huge number of datasets without supervision and instruction. It then groups these datasets into something that can be usefully interpreted. Clustering provides immediate answers about available data, which is helpful if an extensive analysis is not required for action.
Another great application of clustering is if the dataset is composed of a great number of variables. Through clustering, irrelevant groups can be determined and removed from the data set. This is specifically applicable for large datasets where it becomes more challenging to annotate, classify and categorize data points. Since clustering is more focused on the grouping itself, it cuts down the time required for annotating and classifying datasets.
A more structured dataset may still not have the classification needed to draw conclusions. Clustering can provide answers to important dataset questions.
Clustering can identify data anomalies. Due to clustering algorithms’ sensitivity to data points deviation, they can find separate clusters that are closely placed. Determining data anomalies helps in optimizing current data collection tools, leading to more precise results in the long run.
Clustering lets businesses approach customer segments uniquely based on their similarities and attributes, thereby maximizing ROI. In unsupervised machines,
clustering algorithms are especially helpful in grouping uncategorized data into groups that have the same characteristics.
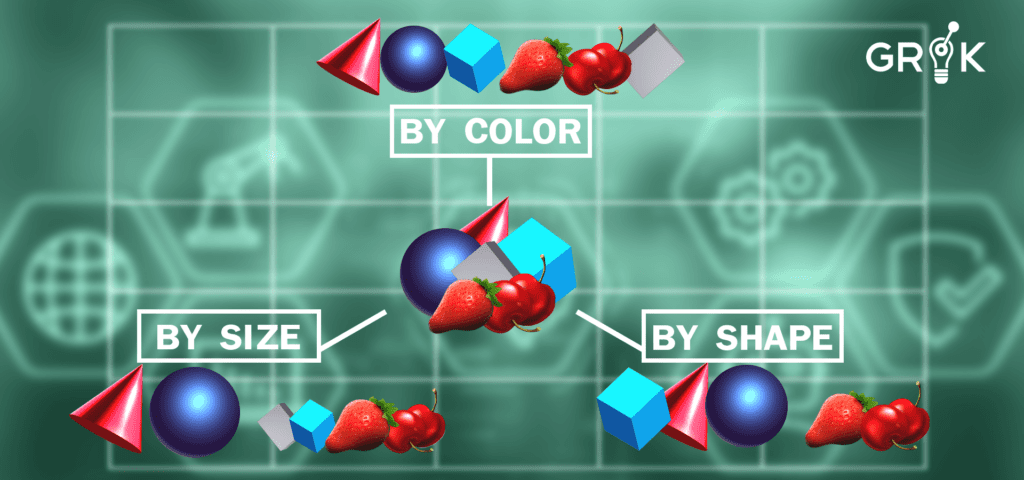
Better patterns can be identified by looking at events from multiple dimensions in order to build a model. Every dimension has a marginally different perspective of how events are connected to each other. Events can be categorized together in a variety of ways, that is by device, by event type, and by device + event type (specific).
For each single dimension, event patterns are examined according to every unique value in the said dimension. For example, if “Device” is the dimension, event patterns for Device A, Device B, and Device C etc. would be analyzed. The event firing patterns for the devices would be compared to check for similarities.
This can be done at scale across tens or hundreds of thousands of different device types. After a pairwise comparison (comparing every unique value pattern to every other) the result is a “distance matrix,” which provides the similarity of every device pattern with every other.
Once this is done, the same method is applied across the other two dimensions– event type and then event type+device. This process produces three distance matrices– one for each dimension– to create a full Grok representational model or the Grok Brain. This is a massive, sophisticated model of how all the events are connected to each other. This can be used to organize future events as they occur.
To cluster new events entering the pipeline, this representational memory or brain is then utilized. Part of the Grok brain is queried to find a similarity score and whether events should be grouped together based on a similarity threshold when new events are received. Grok does this at scale for the entire event stream in real-time.
In addition, the Grok representational memory is constantly learning and updating in real-time based on new events and the patterns they produce, thus becoming even more accurate over time.
The primary use of clustering in machine learning is to extract valuable inferences from many unstructured data sets.
Working with large amounts of data that are not structured makes it logical and necessary to organize that data in ways that make it useful. Clustering does that.
Clustering and classification allow an inclusive overview of important data. And allow users to form actionable conclusions before going deeper into a nuts-and-bolts analysis.
Clustering is a significant component of machine learning, and its importance is indispensable in providing better machine learning techniques.