The well-known “No free lunch” theorem is something you’ve probably heard about if you’re familiar with machine learning in general. This article’s objective is to present the theorem as simply as possible while emphasizing the importance of comprehending its consequences in order to develop an AIOPS strategy.
There is no one machine learning algorithm that will work optimally for all tasks, according to the “No Free Lunch” theory for ML. Therefore, there isn’t a single efficient algorithm that can be used to solve every problem or even a particular problem in a variety of contexts.
There are generally two No Free Lunch theorems, one for Supervised Machine Learning (Wolpert 1996), and the other for search and optimization (Wolpert and Macready 1997).
In this article, we are going to focus more on the one written by David Wolpert for supervised machine learning.
The foundations of this theorem can be found in David Wolpert’s 1996 paper ‘The lack of a Priori Distinctions between Learning Algorithms’, which investigates the potential for producing useful theoretical results using a training data set and a learning algorithm without any target variable assumptions. Wolpert shows using a variety of mathematical models that for every pair of algorithms A and B, there are just as many possible outcomes in which A will perform worse than B as there are in which A would perform better. This is true even if one of the provided algorithms is guessed randomly. Wolpert developed a mathematical proof demonstrating that for all possible problem instances drawn from a uniform probability distribution, the average performance of A and B algorithms is the same.
It is obvious that the assumptions made by these algorithms will not precisely fit all the data sets because machine learning algorithms are created differently for different problems. By extension, it means that there will be an equal number of data sets that a particular method would be unable to accurately predict.
For instance, you decide to meet at 8.30 p.m. on a Saturday night to go out for drinks with your pals. When you glance at your GPS after getting ready and starting the car, it indicates a 40-minute drive. You select a different path, and the time indicated is only 30 minutes, but in order to get to the bar, you must go an additional 5 miles and take this path. Due to your punctuality, this choice is successful. Therefore, the answer to the question “Can we always choose an extra 5 miles route?” is no. This is due to the fact that there is a good chance you will spend extra on gas if you decide to drive outside of peak hours.
Therefore, it is nearly hard to find a machine learning method that is “free”. The rationale behind it is that in order to develop a suitable machine learning issue, you must apply information about your data and analyze the context of the environment we and our data live in. This implies that there is no one machine learning algorithm that is always superior, and there is no usage-independent justification for choosing one method over another.
Building algorithm selection methods as part of the design process is necessary to solve critical AIOPS challenges like Incident Prediction and Problem Identification, just as you would for determining the best hyper-parameters for a specific algorithm. So if any vendor is selling a black-box algorithm or set of algorithms you can be sure that, at least for a portion of the potential users and use cases, it will not be the best algorithm for the job.
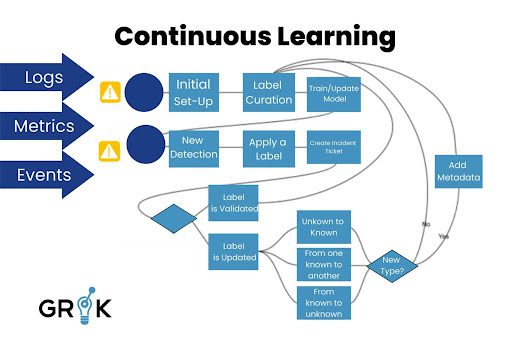
Grok creates features from Detections that are a reflection of the underlying cause’s characteristics. The same metadata, including Name (Port Flapping on Switch), Root cause, Knowledge Article, etc., is used to classify similar detections. Each pattern is recognized by Grok, which also spots occurrences early on in their lifecycle.
Depending on how long they persist prior to remediation action being done, we can conceive of each detection as being a member of a family of incident types that are linked to the same family of underlying causes and have similar service implications. The purpose of incident detection for event data is to determine the root cause and the most effective course of action for each individual detection. The more quickly the issue can be resolved, the faster we can reveal the likely underlying causes and suggested fix actions in the detection’s progression (which could take several hours). The steps to incident detection are as follows:
The objective of Grok is to identify the Incident Type as early as possible in the Incident lifecycle. The evolution of the detection’s morphology, which points to a specific Incident of a specific type, can happen quickly or slowly. Consider the scenario in which the incident of type may appear more than 45 minutes after the underlying cause happened due to current rule-based triggers. These temporal “snapshots” of detection are encoded in the feature space so Grok may see how a specific Detection, particularly those that will eventually give rise to an incident, looks at different phases of its history.
We can give Grok an initial set of labels from which to start progressing through the Incident detection lifecycle by using historical Incident data. Grok then gains knowledge from each incident it discovers; if it successfully classifies an incident, such as one involving routing, it feeds that sample back to Grok for use in developing a new classification model. If Grok misidentified the incident, i.e., it was really a switching issue, then the ticket will be updated with the proper labels as it moves through the remediation process. The next iteration of the categorization model will be created by Grok after taking note of the modified labels. By continually learning how each general class of Incident (such as a file system full issue) presents on the network, Grok will do so. Depending on the applications it supports, a file system filling up can necessitate a very different Run Book and Automation approach.
Grok behaves in the world (action selection and prioritizing) by first observing human behavior, acting similarly to those previously observed, and learning from its mistakes. Grok’s “world” consists of optimizing network and system performance.