
Introduction
With the v5 beta release of Grok®, we’ve introduced an entirely new feature – GrokGuru. This article briefly explains the technical side of how GrokGuru works, how it’s integrated into the Grok ecosystem and how it can help our customers to get the most out of their AIOps insights.
But first, let’s briefly discuss the business use case.
Why We Built GrokGuru
In the technical design process, we asked ourselves a question, which we believe should be the cornerstone of any AI implementation: “What problem does GrokGuru solve?”
We came to an answer based on our customers’ feedback to Grok, the feature requests we got over the years, and the original goal of Grok – to reduce noise and automate the AIOps monitoring pipeline. The problem we noticed was the presentation layer of our application – the clustering results, while easier to understand than raw stream of events, still required the user to have solid expertise in the topic. Without such expertise, it was more difficult to act or make informed decisions based on Grok’s output in a timely manner. Building GrokGuru accelerates this effort by making insights more accessible and reducing the reliance on deep domain expertise.
Real-World Use Case: Speeding Up Problem Solving
The output of Grok clustering consists of, among others, entities we call detections and labels. Each detection represents a cluster of events; each label can be assigned to one or more detections (it’s a unique ID assigned to a recurring detection). Those entities are the main point of interest for our users, as they are the main description of the system state at any given moment.
Let’s consider a practical example – a power cut to a server results in a plethora of events describing the same problem from different points of view. A server is offline, so a watcher service that polled it for data raises timeouts, a website raises HTTP 500 errors because one of the services is down, etc. All those events point to the same issue, so Grok’s clustering will create a detection that groups those events.
Now imagine you’re in the network operations center (NOC) looking at this detection. You can drill down in the Grok UI and identify the underlying issue thanks to the context and expert knowledge you have, right? What happens if you haven’t seen this problem before? You risk losing precious time to investigate.
This is where GrokGuru comes to your help – the detection goes through our summarization pipeline, with GrokGuru creating summaries, probable root causes, and action recommendations designed to make the problem recognizable at first glance, even if you haven’t seen it before. This all happens because GrokGuru can quickly utilize the wealth of information present in the output of Grok clustering.
How GrokGuru Works Under the Hood
I’m going to use our internal architecture diagram and go through it in steps to visualize what makes GrokGuru tick.
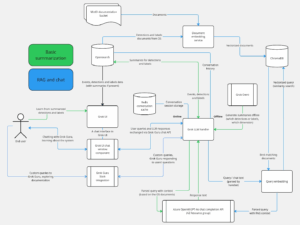
GrokGuru container architecture diagram
Dual Use Modes: Online vs Offline
GrokGuru can work both in an online (interactive) and offline (data presentation) mode. On the diagram, the two modes of work are color-coded, with basic summarization being the data presentation, or offline mode (green).
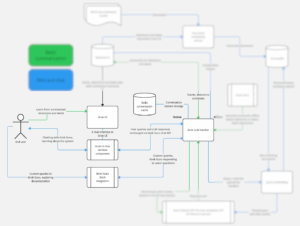
GrokGuru user interactions diagram
As you can see in the highlighted part of the diagram, the user interaction is either just consuming the summarized data via Grok UI or actively conversing with GrokGuru to learn more details.
Let’s discuss how the summarization works.
Summarizing Clusters with AI
As mentioned above, the entities GrokGuru is primarily interested in are detections and labels. In the example given before, we can expect that multiple documents describing events and detections were created by Grok and loaded into the document database we use, OpenSearch.
GrokGuru is a distributed service, with a so-called LLM handler (LLM = Large Language Model) being its point of contact with the rest of the Grok ecosystem. This handler is implemented by an API which is then called for /chat and /summarize requests. The technical challenge here is calling GrokGuru at the right time, asking it to summarize the right detections. This is done offline by Grok Omni, a stream-to-stream system that gets notified of any documents being sent into OpenSearch.
Having a separate system calling GrokGuru’s summarization API was a decision that resulted in greater flexibility. We were not required to implement all the monitoring logic, which would ensure GrokGuru stays up to date with changes in OpenSearch. This in turn made the key component of GrokGuru, the LLM handle, be a much smaller and more focused application. It was easier to design thorough automatic tests and improved the reliability.
Once the handler receives a /summarize request, it retrieves the relevant activation and its events, composes a structured query from their contents and queries the Azure OpenAI service with that query. Data safety is critical in GrokGuru, that’s why we needed to design a proper isolated component architecture in our cloud environment in Azure. The service we’re using for LLM, the Azure OpenAI service, is separate for each customer and deployed in the same region as our database. This way we can ensure there’s no risk of breaking GDPR compliance by making any raw data cross the borders.
Conversational AI with Custom Queries
As you can see in the diagram above, the “RAG and chat” (RAG = Retrieval-Augmented Generation) section marked in blue consists of two online use cases. Our users can either chat with GrokGuru or ask custom queries to it. Both use cases are implemented by the LLM handler as a part of its /chat API.
Technically, the only difference between a custom query and chatting with GrokGuru is the session persistence. In the case of custom queries, our priority is to give a detailed answer, linking any resources GrokGuru bases the response on. This means a custom query doesn’t support any follow-up questions.
The chat, on the other hand, involves conversing with GrokGuru, being able to come back to previous responses, ask for new information, etc. The important component here is our conversation cache, which makes it easy for GrokGuru to always have the relevant chat sessions on hand.
How RAG Powers GrokGuru’s Context
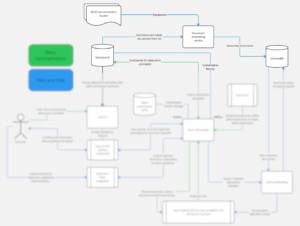
GrokGuru RAG
Awareness
The key part of our RAG solution is a sort of Y-shaped data pipeline, where on one side we’re feeding Grok output into GrokGuru in the form of detections and labels, and project-specific documentation on the other. The output from this pipeline is stored in ChromaDB, a vector database serving as GrokGuru’s context “memory”. The vector database stores the documents in the form of embedding vectors – essentially a long string of numbers representing the text content of a document. Let’s look into this pipeline in more detail.
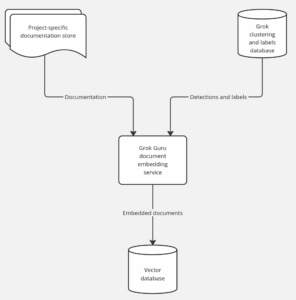
The Y-shaped data pipeline
All incoming information in this pipeline gets processed by our embedding service, an application which implements watchers for documents stored in S3 and clustering results stored in OpenSearch. The embedding service feeds our vector database with documents in vector form, making sure that whenever GrokGuru receives a query, all the relevant context is there, ready to be retrieved by the LLM handler using similarity search.
The architectural decision to make this into a continuous process based on watcher classes was influenced by our desire to keep the core of GrokGuru as simple as possible. This way, the main functionalities of retrieving best-matching documents, composing queries, and communicating with Azure OpenAI Service can be more isolated from the data layer, making it easier to make them reliable at fulfilling their business purpose.
Delegating the vector embedding responsibility to a separate application has the added benefit of easier and faster release and iteration process for the LLM handler component. This in turn empowers our data science team to experiment with the prompting and query composition in a more agile way, responding to our customers’ feedback.
Choosing a Secure and Scalable LLM Provider
Data security and reliability of service were our priorities from day one. When it came to choosing an LLM provider, the desire to avoid sending too much information over the network heavily influenced our decision. Since we’re using Azure as our cloud partner, our multi-tenant systems are divided into Azure regions, it was a natural next step to make GrokGuru a part of this ecosystem.
In our case, Azure OpenAI serves its purpose really well, making sure our customers’ data never leaves the regions they operate in to avoid any potential compliance issues. The service itself has so far been reliable, easy to configure, and reasonably priced.
From my experience, my advice to anyone making a similar decision would be to go with the default provider for the cloud you’re using. In most cases, the performance difference might not justify extra problems with ensuring data safety.
Bringing It All Together
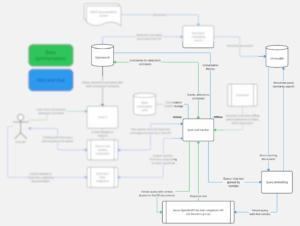
GrokGuru’s communication with Azure OpenAI API
We’ve already discussed how GrokGuru gets used, where it gets data from, how it learns from Grok clustering results and project documentation. Now let’s take a look at a final component that makes it all possible – the Azure OpenAI API.
In the diagram above, the “Query embedding” component is in reality a part of the Grok LLM handler, which means our LLM handler—the heart of GrokGuru—is the only part of the application that connects to Azure OpenAI API. The queries are parsed and enriched with context (retrieved from ChromaDB or straight from OpenSearch) before they get sent to the API.
To optimize our API usage, we’re using a lot of content returned from the LLM to permanently enhance our detections and labels. For that reason as well, the results are cached in the main database and, in the case of chat requests to GrokGuru, in the Redis conversation cache.
Summary: Benefits and Design Highlights
GrokGuru represents a significant evolution in how Grokstream helps customers extract actionable insights from their AiOps data. By integrating Large Language Model capabilities into the Grok v5 ecosystem, we’ve addressed a critical challenge: making complex clustering results immediately understandable to operators regardless of their expertise level.
Key Benefits:
- Accelerated problem resolution:Operators can understand issues at first glance without deep technical knowledge
- Dual-mode operation:Offline summarization for automatic insights and online chat for interactive investigation
- Context-aware responses:RAG implementation ensures answers are grounded in actual system data and documentation
Technical Highlights:
- Distributed architecture:Separate services for embedding, LLM handling, and conversation management ensure reliability and scalability
- Data security first:Azure OpenAI deployment within customer regions ensures GDPR compliance and data sovereignty
- Intelligent pipeline:Y-shaped data flow combines real-time clustering results with project documentation for comprehensive context
Architecture Decisions:
Our design prioritizes simplicity and reliability through:
- Separation of concerns between data processing and LLM operations
- Continuous embedding updates via watcher patterns
- Strategic use of caching layers for performance optimization
- Azure-native integration for seamless multi-tenant support
GrokGuru transforms raw event clusters into actionable intelligence, enabling faster incident response and reducing the expertise barrier for effective AIOps monitoring. This positions Grokstream customers to maximize their operational efficiency while maintaining full control over their data.
Ready to See Grok (and GrokGuru) in Action?
Whether you’re looking to reduce incident response times, empower your frontline teams, or gain deeper insights from your AIOps data—Grok is here to help.
Request a Demo to explore how GrokGuru can accelerate your IT operations strategy.




